概要
Macchinetta Batch Framework (2.x)のアーキテクチャ全体像を説明する。
Macchinetta Batch Framework (2.x)では、"一般的なバッチ処理システム"で説明したとおり TERASOLUNA Batch Framework for Java (5.x)を中心としたOSSの組み合わせを利用して実現する。
TERASOLUNA Batch Framework for Java (5.x)の階層アーキテクチャを含めたMacchinetta Batch Framework (2.x)の構成概略図を以下に示す。
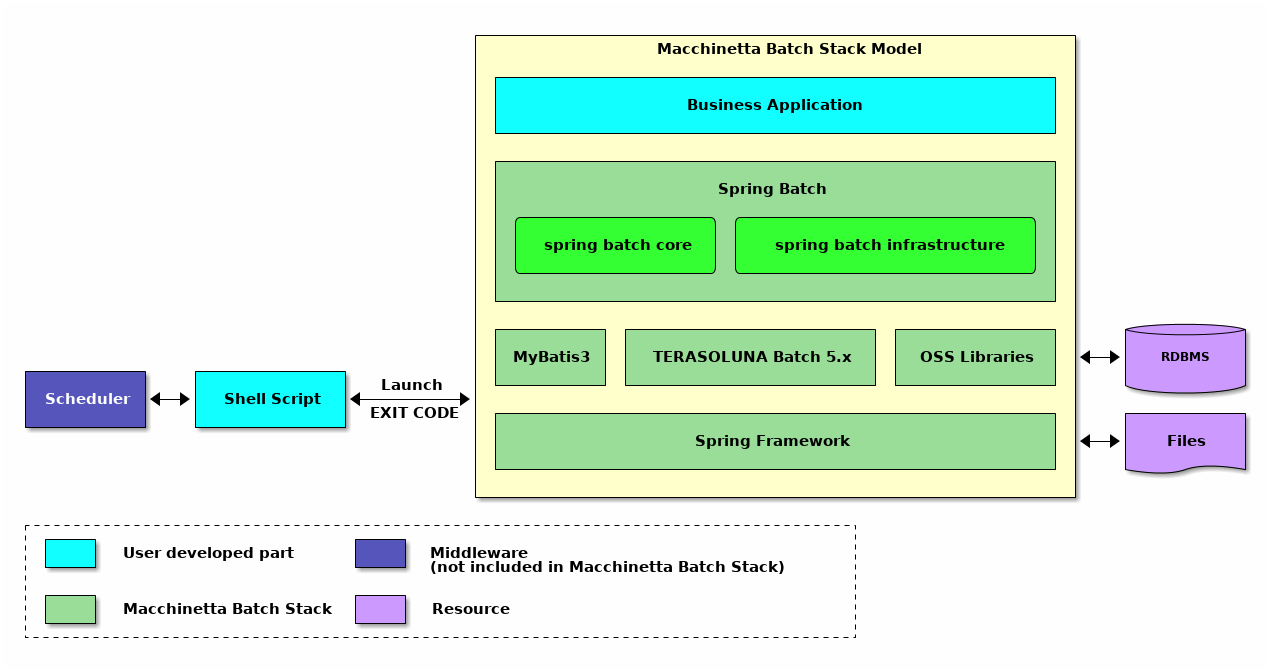
- アプリケーション
-
開発者によって書かれたすべてのジョブ定義およびビジネスロジック。
- コア
-
TERASOLUNA Batch Framework for Java (5.x) が提供するバッチジョブを起動し、制御するために必要なコア・ランタイム・クラス。
- インフラストラクチャ
-
TERASOLUNA Batch Framework for Java (5.x) が提供する開発者およびコアフレームワーク自体が利用する一般的なItemReader/ItemProcessor/ItemWriterの実装。
ジョブの構成要素
ジョブの構成要素を説明するため、ジョブの構成概略図を下記に示す。
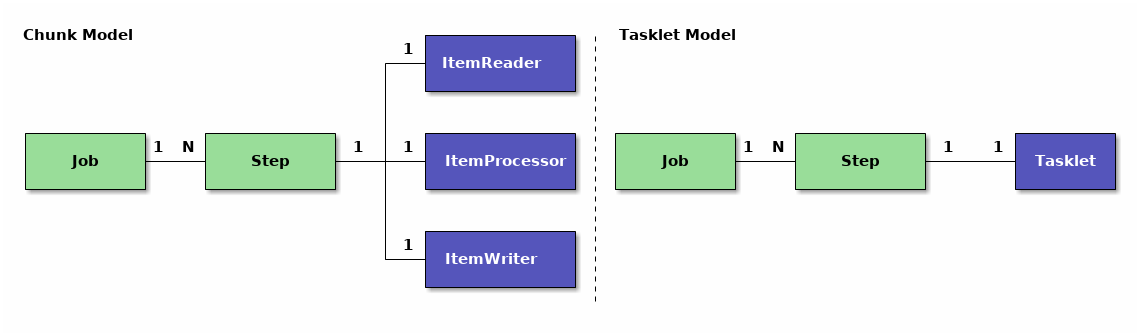
この節では、ジョブとステップについて構成すべき粒度の指針も含めて説明をする。
ジョブ
ジョブとは、バッチ処理全体をカプセル化するエンティティであり、ステップを格納するためのコンテナである。
1つのジョブは、1つ以上のステップで構成することができる。
ジョブの定義は、XMLによるBean定義ファイルに記述する。 ジョブ定義ファイルには複数のジョブを定義することができるが、ジョブの管理が煩雑になりやすくなる。
従って、Macchinetta Batch Framework (2.x)では以下の指針とする。
1ジョブ=1ジョブ定義ファイル
ステップ
ステップとは、バッチ処理を制御するために必要な情報を定義したものである。 ステップにはチャンクモデルとタスクレットモデルを定義することができる。
- チャンクモデル
-
-
ItemReader、ItemProcessor、およびItemWriterで構成される。
-
- タスクレットモデル
-
-
Taskletだけで構成される。
-
チャンクモデル/タスクレットモデルの構成要素を実装したクラスは、@Componentを付与してBean定義する。
"バッチ処理で考慮する原則と注意点"にあるとおり、
単一のバッチ処理では、可能な限り簡素化し、複雑な論理構造を避ける必要がある。
従って、Macchinetta Batch Framework (2.x)では以下の指針とする。
1ステップ=1バッチ処理=1ビジネスロジック
|
チャンクモデルでのビジネスロジック分割
1つのビジネスロジックが複雑で規模が大きくなる場合、ビジネスロジックを分割することがある。 概略図を見るとわかるとおり、1つのステップには1つのItemProcessorしか設定できないため、ビジネスロジックの分割ができないように思える。 しかし、CompositeItemProcssorという複数のItemProcessorをまとめるItemProcessorがあり、 この実装を使うことでビジネスロジックを分割して実行することができる。 |
|
Macchinetta Batch 2.xでのBean定義
Macchinetta Batch 2.xでのBean定義は、以下を前提とする。
|
ステップの実装方式
チャンクモデル
チャンクモデルの定義と使用目的を説明する。
- 定義
-
ItemReader、ItemProcessorおよびItemWriter実装とチャンク数をChunkOrientedTaskletに設定する。それぞれの役割を説明する。
-
ChunkOrientedTasklet・・・ItemReader/ItemProcessorを呼び出し、チャンクを作成する。作成したチャンクをItemWriterへ渡す。
-
ItemReader・・・入力データを読み込む。
-
ItemProcessor・・・読み込んだデータを加工する。
-
ItemWriter・・・加工されたデータをチャンク単位で出力する。 :: チャンクモデルの概要は、 "チャンクモデル" を参照。
-
<batch:job id="exampleJob">
<batch:step id="exampleStep">
<batch:tasklet>
<batch:chunk reader="reader"
processor="processor"
writer="writer"
commit-interval="100" />
</batch:tasklet>
</batch:step>
</batch:job>- 使用目的
-
一定件数のデータをまとめて処理を行うため、大量データを取り扱う場合に用いられる。
タスクレットモデル
タスクレットモデルの定義と使用目的を説明する。
- 定義
-
Tasklet実装だけを設定する。
タスクレットモデルの概要は、 "タスクレットモデル" を参照。
<batch:job id="exampleJob">
<batch:step id="exampleStep">
<batch:tasklet ref="myTasklet">
</batch:step>
</batch:job>- 使用目的
-
システムコマンドの実行など、入出力を伴わない処理を実行するために用いられる。
また、一括でデータをコミットしたい場合にも用いられる。
チャンクモデルとタスクレットモデルの対比
チャンクモデルとタスクレットモデルの差異について説明する。 詳細については各機能の節を参照してもらい、ここでは概略のみにとどめる。
| 項目 | チャンクモデル | タスクレットモデル |
|---|---|---|
構成要素 |
ItemReader、ItemProcessor、ItemWriter、ChunkOrientedTaskletで構成される。 |
Taksletのみで構成される。 |
チャンク単位にトランザクションが発生する。トランザクション制御は一定件数ごとにトランザクションを確定する中間コミット方式のみ。 |
1トランザクションで処理する。トランザクション制御は、全件を1トランザクションで確定する一括コミット方式と中間コミット方式のいずれかを利用可能。 前者はSpring Batchが持つトランザクション制御の仕組みを利用するが、後者はユーザにてトランザクションを直接操作する。 |
|
リランおよび、ステートレスリスタート(件数ベースリスタート)、ステートフルリスタート(処理状態を判断したリスタート)が利用できる。 |
リランのみ利用することを原則とする。処理状態を判断したリスタートが利用できる。 |
|
Spring Batch提供の各種Listenerインタフェースを使うことでハンドリング処理が容易になっている。try-catchによる独自実装も可能。 |
タスクレット実装内にて独自にtry-catchを実装することが基本。ChunkListenerインタフェースの利用も可能。 |
ジョブの起動方式
ジョブの起動方式について説明する。ジョブの起動方式には以下のものがある。
それぞれの起動方式について説明する。
同期実行方式
同期実行方式とは、ジョブを起動してからジョブが終了するまで起動元へ制御が戻らない実行方式である。
ジョブスケジューラからジョブを起動する概略図を示す。

-
ジョブスケジューラからジョブを起動するためのシェルスクリプトを起動する。
シェルスクリプトから終了コード(数値)が返却するまでジョブスケジューラは待機する。 -
シェルスクリプトからジョブを起動するために
CommandLineJobRunnerを起動する。
CommandLineJobRunnerから終了コード(数値)が返却するまでシェルスクリプトは待機する。 -
CommandLineJobRunnerはジョブを起動する。ジョブは処理終了後に終了コード(文字列)をCommandLineJobRunnerへ返却する。
CommandLineJobRunnerは、ジョブから返却された終了コード(文字列)から終了コード(数値)に変換してシェルスクリプトへ返却する。
非同期実行方式
非同期実行方式とは、起動元とは別の実行基盤(別スレッドなど)でジョブを実行することで、ジョブ起動後すぐに起動元へ制御が戻る方式である。 この方式の場合、ジョブの実行結果はジョブ起動とは別の手段で取得する必要がある。
Macchinetta Batch Framework (2.x)では、以下に示す2とおりの方法について説明をする。
|
その他の非同期実行方式
MQなどのメッセージを利用して非同期実行を実現することもできるが、ジョブ実行のポイントは同じであるため、Macchinetta Batch Framework (2.x)では説明は割愛する。 |
非同期実行方式(DBポーリング)
"非同期実行(DBポーリング)"とは、 ジョブ実行の要求をデータベースに登録し、その要求をポーリングして、ジョブを実行する方式である。
Macchinetta Batch Framework (2.x)で利用しているTERASOLUNA Batch Framework for Java (5.x)は、DBポーリング機能を提供している。提供しているDBポーリングによる起動の概略図を示す。
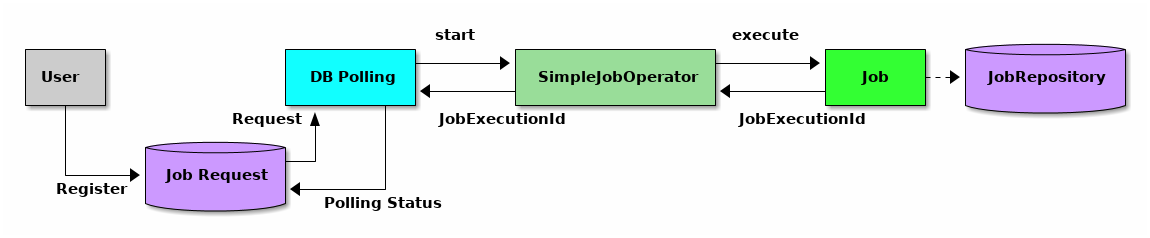
-
ユーザはデータベースへジョブ要求を登録する。
-
DBポーリング機能は、定期的にジョブ要求の登録を監視していて、登録されたことを検知すると該当するジョブを実行する。
-
SimpleJobOperatorからジョブを起動し、ジョブ終了後に
JobExecutionIdを受け取る。 -
JobExecutionIdとは、ジョブ実行を一意に識別するIDであり、このIDを使ってJobRepositoryから実行結果を参照する。
-
ジョブの実行結果は、Spring Batchの仕組みによって、JobRepositoryへ登録される。
-
DBポーリング自体が非同期で実行されている。
-
-
DBポーリング機能は、SimpleJobOperatorから返却されたJobExecutionIdとスタータスを起動したジョブ要求に対して更新を行う。
-
ジョブの処理経過・結果は、JobExecutionIdを利用して別途参照を行う。
非同期実行方式(Webコンテナ)
"非同期実行(Webコンテナ)"とは、 Webコンテナ上のWebアプリケーションへのリクエストを契機にジョブを非同期実行する方式である。 Webアプリケーションは、ジョブの終了を待たずに起動後すぐにレスポンスを返却することができる。

-
クライアントからWebアプリケーションへリクエストを送信する。
-
Webアプリケーションは、リクエストから要求されたジョブを非同期実行する。
-
SimpleJobOperatorからジョブを起動直後に
JobExecutionIdを受け取る。 -
ジョブの実行結果は、Spring Batchの仕組みによって、JobRepositoryへ登録される。
-
-
Webアプリケーションは、ジョブの終了を待たずにクライアントへレスポンスを返信する。
-
ジョブの処理経過・結果は、JobExecutionIdを利用して別途参照を行う。
また、 Macchinetta Server Framework (1.x)で構築されるWebアプリケーションと連携することも可能である。
利用する際の検討ポイント
Macchinetta Batch Framework (2.x)を利用する際の検討ポイントを示す。
- ジョブ起動方法
-
- 同期実行方式
-
スケジュールどおりにジョブを起動したり、複数のジョブを組み合わせてバッチ処理行う場合に利用する。
- 非同期実行方式(DBポーリング)
-
ディレード処理、処理時間が短いジョブの連続実行、大量ジョブの集約などに利用する。
- 非同期実行方式(Webコンテナ)
-
DBポーリングと同様だが、起動までの即時性が求められる場合にはこちらを利用する。
- 実装方式