|
前提
チュートリアルの進め方で説明しているとおり、 既に作成済みのジョブに対して、非同期実行していく形式とする。 非同期実行方式にはDBポーリングを利用する方式と Webコンテナを利用する方式があるが、 チュートリアルではDBポーリングを利用する方式の説明を行う。 |
概要
DBポーリングを利用してジョブを非同期実行する。
なお、詳細についてはMacchinetta Batch 2.x 開発ガイドラインの非同期実行(DBポーリング)を参照。
また、アプリケーションの背景、処理概要、業務仕様は、バッチジョブの実装の各節を参照。
以降では、DBポーリングによるジョブの非同期実行方法を以下の手順で説明する。
準備
非同期実行(DBポーリング)を行うための準備作業を実施する。
実施する作業は以下のとおり。
ポーリング処理の設定
非同期実行に必要な設定は、batch-application.propertiesで行う。
ブランクプロジェクトには設定済みであるため、詳細な説明は割愛する。
各項目の説明は各種設定のポーリング処理の設定を参照。
# TERASOLUNA AsyncBatchDaemon settings.
# (1)
async-batch-daemon.scheduler.size=1
async-batch-daemon.schema.script=classpath:org/terasoluna/batch/async/db/schema-h2.sql
# (2)
async-batch-daemon.job-concurrency-num=3
# (3)
async-batch-daemon.polling-interval=10000
# (4)
async-batch-daemon.polling-initial-delay=1000
# (5)
async-batch-daemon.polling-stop-file-path=/tmp/stop-async-batch-daemon| 項番 | 説明 |
|---|---|
(1) |
DBポーリング処理で起動される |
(2) |
ポーリング時に一括で取得する件数を設定する。 |
(3) |
ポーリング周期(ミリ秒単位)を設定する。 |
(4) |
ポーリング初回起動遅延時間(ミリ秒単位)を設定する。 |
(5) |
非同期バッチデーモンを停止させるための終了ファイルパスを設定する。 |
ジョブの設定
非同期実行する対象のジョブは、async-batch-daemon.xmlのautomaticJobRegistrarに設定する。
例としてデータベースアクセスでデータ入出力を行うジョブ(チャンクモデル)を指定した設定を以下に示す。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:jdbc="http://www.springframework.org/schema/jdbc"
xmlns:c="http://www.springframework.org/schema/c"
xmlns:p="http://www.springframework.org/schema/p"
xmlns:task="http://www.springframework.org/schema/task"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans https://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/jdbc https://www.springframework.org/schema/jdbc/spring-jdbc.xsd
http://www.springframework.org/schema/task https://www.springframework.org/schema/task/spring-task.xsd
http://www.springframework.org/schema/context https://www.springframework.org/schema/context/spring-context.xsd">
<!-- omitted -->
<bean id="automaticJobRegistrar" class="org.springframework.batch.core.configuration.support.AutomaticJobRegistrar">
<property name="applicationContextFactories">
<bean class="org.springframework.batch.core.configuration.support.ClasspathXmlApplicationContextsFactoryBean"
p:resources="classpath:/META-INF/jobs/dbaccess/jobPointAddChunk.xml" /> <!-- (1) -->
</property>
<property name="jobLoader">
<bean class="org.springframework.batch.core.configuration.support.DefaultJobLoader"
p:jobRegistry-ref="jobRegistry" />
</property>
</bean>
<!-- omitted -->
</beans>| 項番 | 説明 |
|---|---|
(1) |
非同期実行する対象ジョブのBean定義ファイルを指定する。 |
|
ジョブ設計上の留意点
非同期実行(DBポーリング)の特性上、同一ジョブの並列実行が可能になっているので、並列実行した場合に同一ジョブが影響を与えないようにする必要がある。 本チュートリアルでは、データベースアクセスのジョブとファイルアクセスのジョブで同じジョブIDを用いている。 チュートリアルの中で、これらのジョブを並列実行することはないが、同じジョブIDのジョブを複数指定する場合はエラーとなってしまうため、 ジョブの設計時に留意する必要がある。 |
入力リソースの設定
非同期実行でジョブを実行する際の入力リソース(データベース or ファイル)の設定を行う。
ここでは、正常系データを利用するジョブを実行する。
データベースアクセスするジョブとファイルアクセスするジョブの場合の入力リソースの設定を以下に示す。
- データベースアクセスするジョブの場合
-
batch-application.propertiesのDatabase Initializeのスクリプトを以下のとおり設定する。
# Database Initialize
tutorial.create-table.script=file:sqls/create-member-info-table.sql
tutorial.insert-data.script=file:sqls/insert-member-info-data.sql
#tutorial.insert-data.script=file:sqls/insert-member-info-error-data.sql- ファイルアクセスするジョブの場合
-
事前に、入力ファイルが配備されていること、および出力ディレクトリが存在することを確認しておくこと。
-
入力ファイル
-
files/input/input-member-info-data.csv
-
-
出力ディレクトリ
-
files/output/
-
-
|
本チュートリアルにおける入力リソースのデータ準備について
データベースアクセスするジョブの場合、非同期バッチデーモン起動時(ApplicationContext生成時)にINSERTのSQLを実行し、 データベースにデータを準備している。 ファイルアクセスするジョブの場合、入力ファイルをディレクトリに配置し、 ジョブ要求テーブルへジョブ情報の登録時にそのジョブ情報のパラメータ部として入出力ファイルのパスを指定する。 |
非同期バッチデーモンを起動
Macchinetta Batch 2.xが提供するAsyncBatchDaemonを起動する。
実行構成を以下のとおり作成し、非同期バッチデーモンを起動する。
作成手順はRun Configuration(実行構成)の作成を参照。
| 項目名 | 値 |
|---|---|
Name |
Run Job With AsyncBatchDaemon |
Project |
macchinetta-batch-tutorial |
Main class |
org.terasoluna.batch.async.db.AsyncBatchDaemon |
非同期バッチデーモンを起動すると、ポーリングプロセスが10秒間隔(batch-application.propertiesのasync-batch-daemon.polling-intervalに指定したミリ秒)で実行される。
ログの出力例を以下に示す。
このログではポーリングプロセスが3回実行されたことがわかる。
[2020/03/10 17:26:03] [main] [o.t.b.a.d.AsyncBatchDaemon] [INFO ] Async Batch Daemon start.
(.. omitted)
[2020/03/10 17:26:05] [main] [o.s.s.c.ThreadPoolTaskExecutor] [INFO ] Initializing ExecutorService
[2020/03/10 17:26:05] [main] [o.s.s.c.ThreadPoolTaskScheduler] [INFO ] Initializing ExecutorService 'daemonTaskScheduler'
[2020/03/10 17:26:05] [main] [o.t.b.a.d.AsyncBatchDaemon] [INFO ] Async Batch Daemon will start watching the creation of a polling stop file. [Path:\tmp\stop-async-batch-daemon]
[2020/03/10 17:26:06] [daemonTaskScheduler-1] [o.t.b.a.d.JobRequestPollTask] [INFO ] Polling processing.
[2020/03/10 17:26:16] [daemonTaskScheduler-1] [o.t.b.a.d.JobRequestPollTask] [INFO ] Polling processing.
[2020/03/10 17:26:26] [daemonTaskScheduler-1] [o.t.b.a.d.JobRequestPollTask] [INFO ] Polling processing.ジョブ情報をジョブ要求テーブルに登録
ジョブを実行するための情報をジョブ要求テーブル(batch_job_request)に登録するSQL(INSERT文)を発行する。
ジョブ要求テーブルのテーブル仕様はジョブ要求テーブルの構造を参照。
STS上でSQLを実行する方法を以下に記す。
-
Database Browserを表示する。
Database Browserの表示手順はDBeaverを使用してデータベースを参照するを参照。
-
SQLエディタを開く。
[H2 Embedded]を右クリックし、[最近のSQLエディタ]をクリックする。
-
SQLを記述する。
データベースアクセスするジョブとファイルアクセスするジョブを実行するためのSQLをチャンクモデルの例で以下に示す。
- データベースアクセスするジョブの場合
-
記述するSQLを以下に示す。
INSERT INTO batch_job_request(job_name,job_parameter,polling_status,create_date)
VALUES ('jobPointAddChunk', '', 'INIT', current_timestamp);- ファイルアクセスするジョブの場合
-
記述するSQLを以下に示す。
INSERT INTO batch_job_request(job_name,job_parameter,polling_status,create_date)
VALUES ('jobPointAddChunk', 'inputFile=files/input/input-member-info-data.csv,outputFile=files/output/output-member_info_out.csv', 'INIT', current_timestamp);SQL記述後のイメージを以下に記す。
ここでは、データベースアクセスするジョブの実行要求用SQLを記述している。
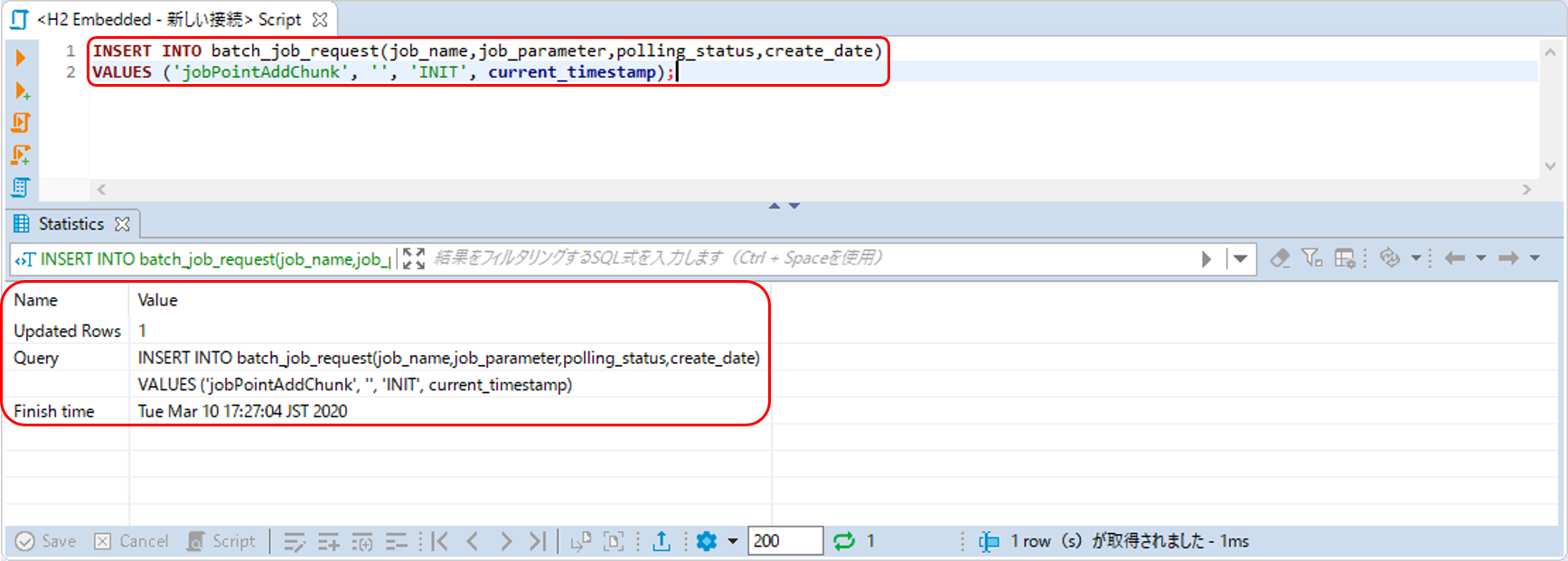
-
ジョブの実行要求用SQLを入力し、[Ctrl]キー + [S]キーで保存する。
-
[Ctrl]キー + [Enter]キーでSQLを実行する。
-
[Statistics]に更新したRowカウント、実行したクエリ、クエリが完了した時間が出力される。
-
ジョブ要求テーブルを確認する。
下図のとおり、ジョブ要求テーブルにジョブを実行するための情報が登録されていることを確認する。
POLLING_STATUSはINITで登録したが、既にポーリングが行われた場合は、POLLING_STATUSがPOLLEDもしくはEXECUTEDとなっている。
POLLING_STATUSの詳細についてはポーリングステータス(polling_status)の遷移パターンを参照。

ジョブの実行と結果の確認
非同期実行対象ジョブの実行結果を確認する。
コンソールログの確認
Console Viewを開き、以下の内容のログが出力されていることを確認する。
-
処理が完了(COMPLETED)し、例外が発生していないこと。
(.. omitted)
[2020/03/10 17:27:06] [daemonTaskScheduler-1] [o.t.b.a.d.JobRequestPollTask] [INFO ] Polling processing.
[2020/03/10 17:27:06] [daemonTaskExecutor-1] [o.s.b.c.l.s.SimpleJobOperator] [INFO ] Checking status of job with name=jobPointAddChunk
[2020/03/10 17:27:06] [daemonTaskExecutor-1] [o.s.b.c.l.s.SimpleJobOperator] [INFO ] Attempting to launch job with name=jobPointAddChunk and parameters=
[2020/03/10 17:27:06] [daemonTaskExecutor-1] [o.s.b.c.l.s.SimpleJobLauncher] [INFO ] Job: [FlowJob: [name=jobPointAddChunk]] launched with the following parameters: [{jsr_batch_run_id=158}]
[2020/03/10 17:27:07] [daemonTaskExecutor-1] [o.s.b.c.j.SimpleStepHandler] [INFO ] Executing step: [jobPointAddChunk.step01]
[2020/03/10 17:27:07] [daemonTaskExecutor-1] [o.s.b.c.s.AbstractStep] [INFO ] Step: [jobPointAddChunk.step01] executed in 191ms
[2020/03/10 17:27:07] [daemonTaskExecutor-1] [o.s.b.c.l.s.SimpleJobLauncher] [INFO ] Job: [FlowJob: [name=jobPointAddChunk]] completed with the following parameters: [{jsr_batch_run_id=158}] and the following status: [COMPLETED] in 246ms
[2020/03/10 17:27:16] [daemonTaskScheduler-1] [o.t.b.a.d.JobRequestPollTask] [INFO ] Polling processing.終了コードの確認
非同期実行の場合、STSのDebug Viewで実行対象ジョブの終了コードを確認することはできない。
ジョブの実行状態はジョブ実行状態の確認で確認する。
出力リソースの確認
実行したジョブによって出力リソース(データベース or ファイル)を確認する。
データベースアクセスするジョブの場合
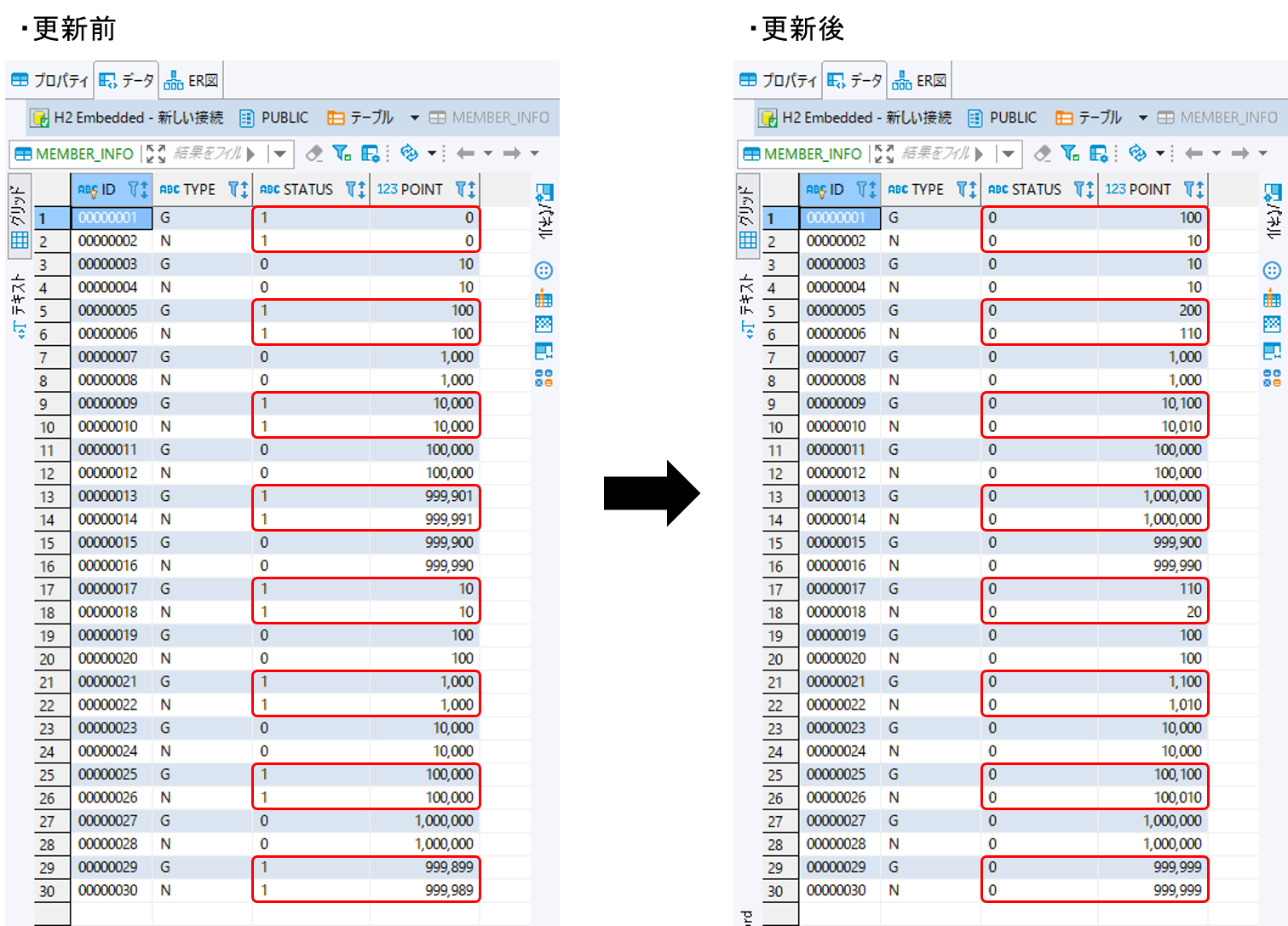
更新前後の会員情報テーブルの内容を比較し、確認内容のとおりとなっていることを確認する。
確認手順はData Source Explorerを使用してデータベースを参照するを参照。
- 確認内容
-
-
statusカラム
-
"1"(処理対象)から"0"(初期状態)に更新されていること
-
-
pointカラム
-
ポイント加算対象について、会員種別に応じたポイントが加算されていること
-
typeカラムが"G"(ゴールド会員)の場合は100ポイント
-
typeカラムが"N"(一般会員)の場合は10ポイント
-
-
1,000,000(上限値)を超えたレコードが存在しないこと
-
-
更新前後の会員情報テーブルの内容を以下に示す。
ファイルアクセスするジョブの場合
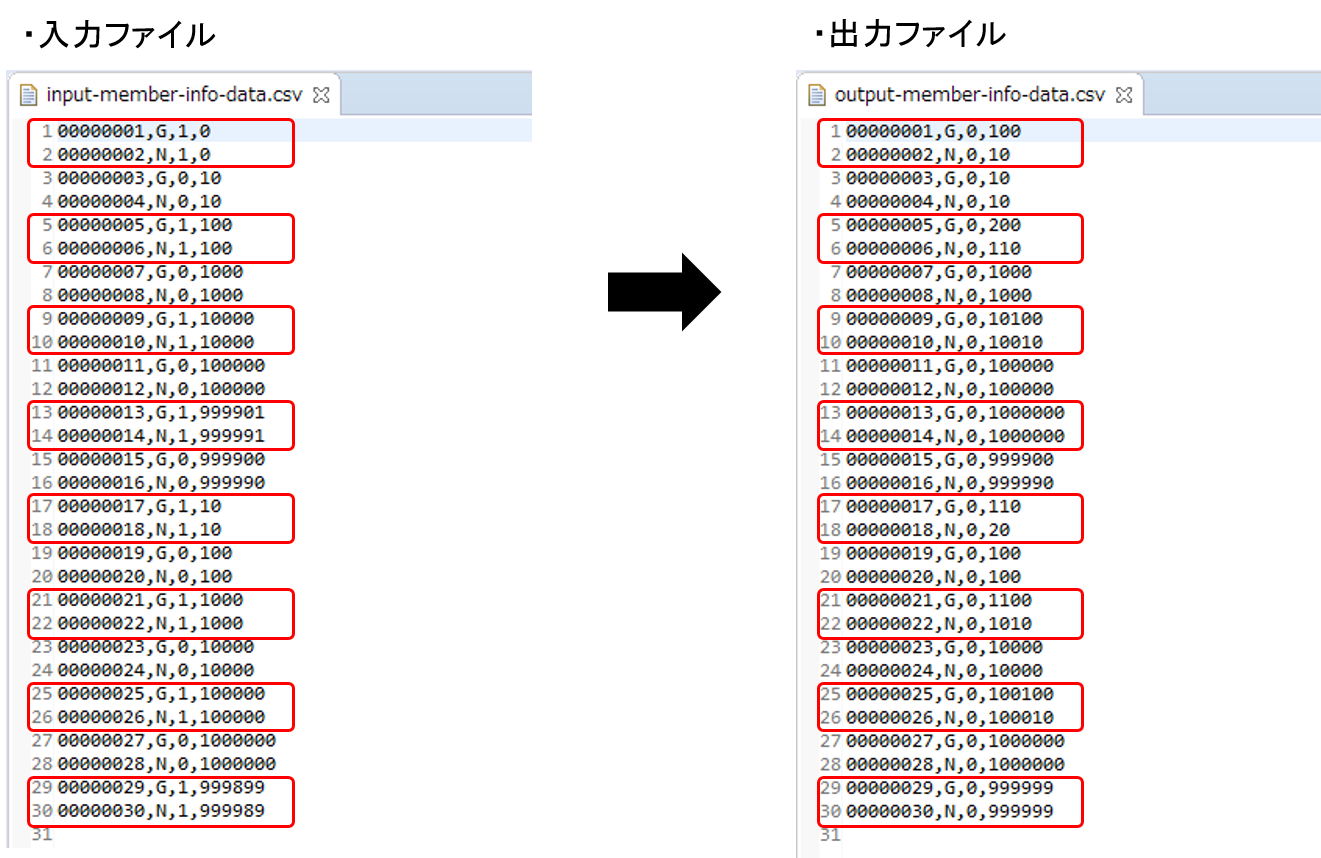
会員情報ファイルの入出力内容を比較し、確認内容のとおりとなっていることを確認する。
- 確認内容
-
-
出力ディレクトリに会員情報ファイルが出力されていること
-
出力ファイル: files/output/output-member-info-data.csv
-
-
statusフィールド
-
"1"(処理対象)から"0"(初期状態)に更新されていること
-
-
pointフィールド
-
ポイント加算対象について、会員種別に応じたポイントが加算されていること
-
typeフィールドが"G"(ゴールド会員)の場合は100ポイント
-
typeフィールドが"N"(一般会員)の場合は10ポイント
-
-
1,000,000(上限値)を超えたレコードが存在しないこと
-
-
会員情報ファイルの入出力内容を以下に示す。
ファイルのフィールドはid(会員番号)、type(会員種別)、status(商品購入フラグ)、point(ポイント)の順で出力される。
非同期バッチデーモンの停止
終了ファイルを作成し、非同期バッチデーモンを停止する。
ポーリング処理の設定で設定したとおり、 C:\tmpにstop-async-batch-daemonファイル(空ファイル)を作成する。
STSのコンソールで以下のとおり非同期バッチデーモンが停止していることを確認する。
(.. omitted)
[2020/03/10 17:32:17] [daemonTaskScheduler-1] [o.t.b.a.d.JobRequestPollTask] [INFO ] Polling processing.
[2020/03/10 17:32:26] [main] [o.t.b.a.d.AsyncBatchDaemon] [INFO ] Async Batch Daemon has detected the polling stop file, and then shutdown now!
[2020/03/10 17:32:26] [main] [o.s.s.c.ThreadPoolTaskScheduler] [INFO ] Shutting down ExecutorService 'daemonTaskScheduler'
[2020/03/10 17:32:26] [main] [o.s.s.c.ThreadPoolTaskExecutor] [INFO ] Shutting down ExecutorService
[2020/03/10 17:32:26] [main] [o.t.b.a.d.JobRequestPollTask] [INFO ] JobRequestPollTask is called shutdown.
[2020/03/10 17:32:26] [main] [o.s.s.c.ThreadPoolTaskScheduler] [INFO ] Shutting down ExecutorService 'daemonTaskScheduler'
[2020/03/10 17:32:26] [main] [o.s.s.c.ThreadPoolTaskExecutor] [INFO ] Shutting down ExecutorService
[2020/03/10 17:32:26] [main] [o.t.b.a.d.AsyncBatchDaemon] [INFO ] Async Batch Daemon stopped after all jobs completed.ジョブ実行状態の確認
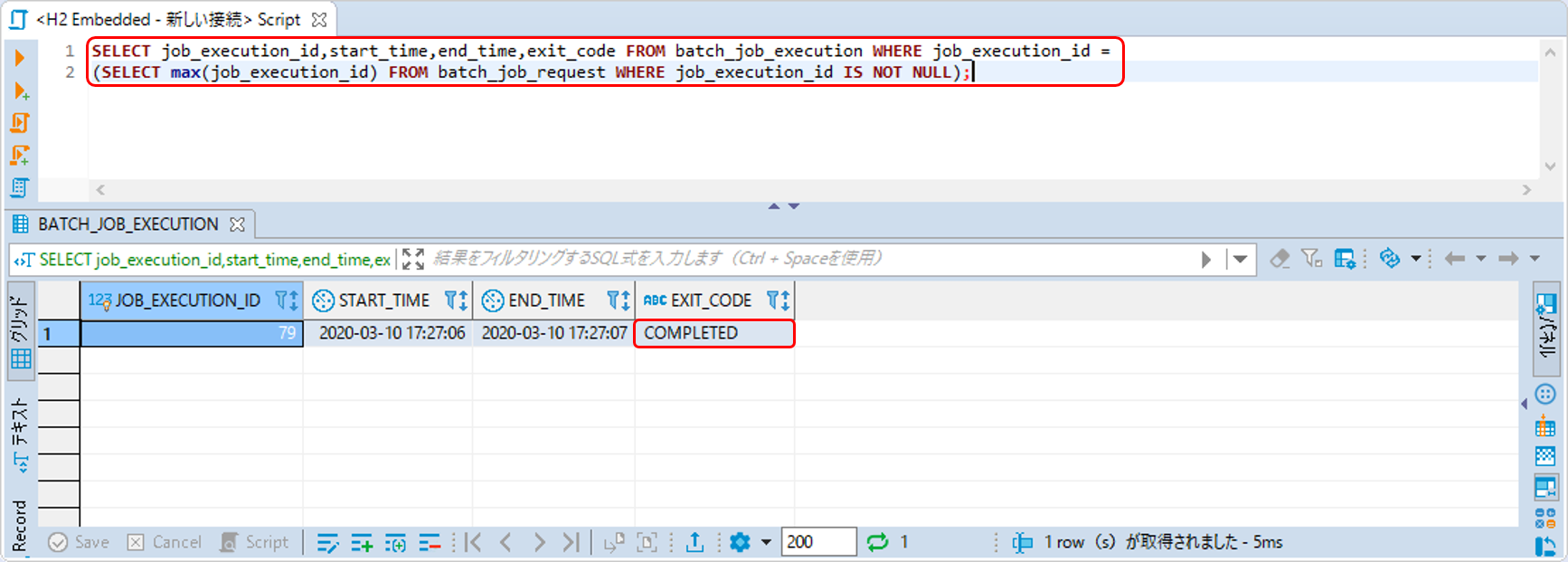
JobRepositoryのメタデータテーブルでジョブの状態・実行結果を確認する。ここでは、batch_job_executionを参照する。
ジョブの状態を確認するためのSQLを以下に示す。
SELECT job_execution_id,start_time,end_time,exit_code FROM batch_job_execution WHERE job_execution_id =
(SELECT max(job_execution_id) FROM batch_job_request WHERE job_execution_id IS NOT NULL);このSQLでは、最後に実行されたジョブの実行状態を取得するようにしている。
SQLの実行結果は、STS上でSQL実行後に表示されるSQL Results Viewにて確認できる。
下図のとおり、終了コード(EXIT_CODE)がCOMPLETED(正常終了)となっていることを確認する。
なお、ジョブの終了コードとプロセスの終了コードのマッピングについては、終了コードのマッピングを参照。