概要
ファイルアクセスでデータ入出力を行うジョブを作成する。
なお、詳細についてはMacchinetta Batch 2.x 開発ガイドラインのファイルアクセスを参照。
作成するアプリケーションの説明の 背景、処理概要、業務仕様を以下に再掲する。
背景
とある量販店では、会員に対してポイントカードを発行している。
会員には「ゴールド会員」「一般会員」の会員種別が存在し、会員種別に応じたサービスを提供している。
今回そのサービスの一環として、月内に商品を購入した会員のうち、
会員種別が「ゴールド会員」の場合は100ポイント、「一般会員」の場合は10ポイントを月末に加算することにした。
業務仕様
業務仕様は以下のとおり。
-
商品購入フラグが"1"(処理対象)の場合に、会員種別に応じてポイントを加算する
-
会員種別が"G"(ゴールド会員)の場合は100ポイント、"N"(一般会員)の場合は10ポイント加算する
-
-
商品購入フラグはポイント加算後に"0"(初期状態)に更新する
-
ポイントの上限値は1,000,000ポイントとする
-
ポイント加算後に1,000,000ポイントを超えた場合は、1,000,000ポイントに補正する
ファイル仕様
入出力リソースとなる会員情報ファイルの仕様は以下のとおり。
| No | フィールド名 | データ型 | 桁数 | 説明 |
|---|---|---|---|---|
1 |
会員番号 |
文字列 |
8 |
会員を一意に示す8桁固定の番号を表す。 |
2 |
会員種別 |
文字列 |
1 |
会員の種別を以下のとおり表す。 |
3 |
商品購入フラグ |
文字列 |
1 |
月内に商品を買ったかどうかを表す。 |
4 |
ポイント |
数値 |
7 |
会員の保有するポイントを表す。 |
このチュートリアルではヘッダレコード、フッタレコードは扱わないこととしているため、 ヘッダレコード、フッタレコードの扱いやファイルフォーマットについては、ファイルアクセスを参照。
ジョブの概要
ここで作成するファイルアクセスでデータ入出力を行うジョブの概要を把握するために、 処理フローおよび処理シーケンスを以下に示す。
処理シーケンスではトランザクション制御の範囲について触れているが、ファイルの場合は擬似的なトランザクション制御を行うことで実現している。 詳細は、非トランザクショナルなデータソースに対する補足を参照。
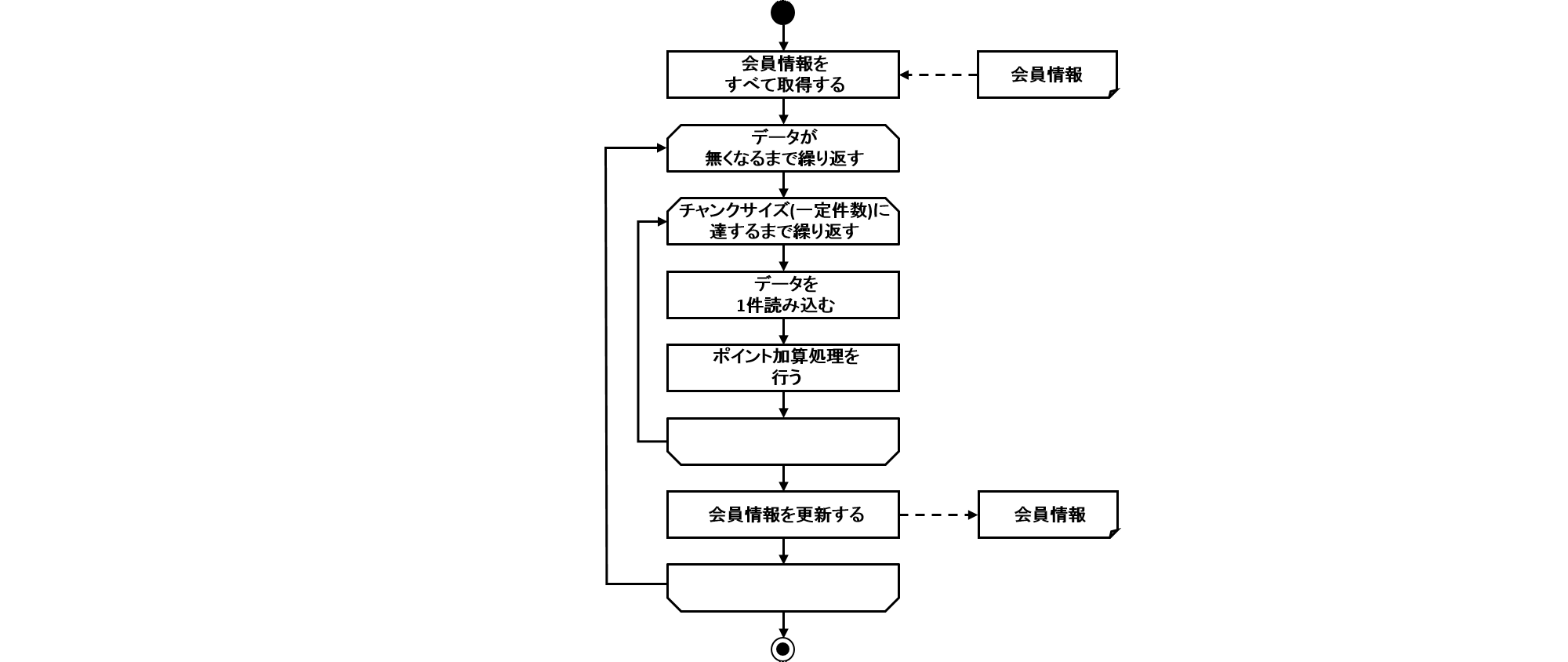
- 処理フロー概要
-
処理フローの概要を以下に示す。
- チャンクモデルの場合の処理シーケンス
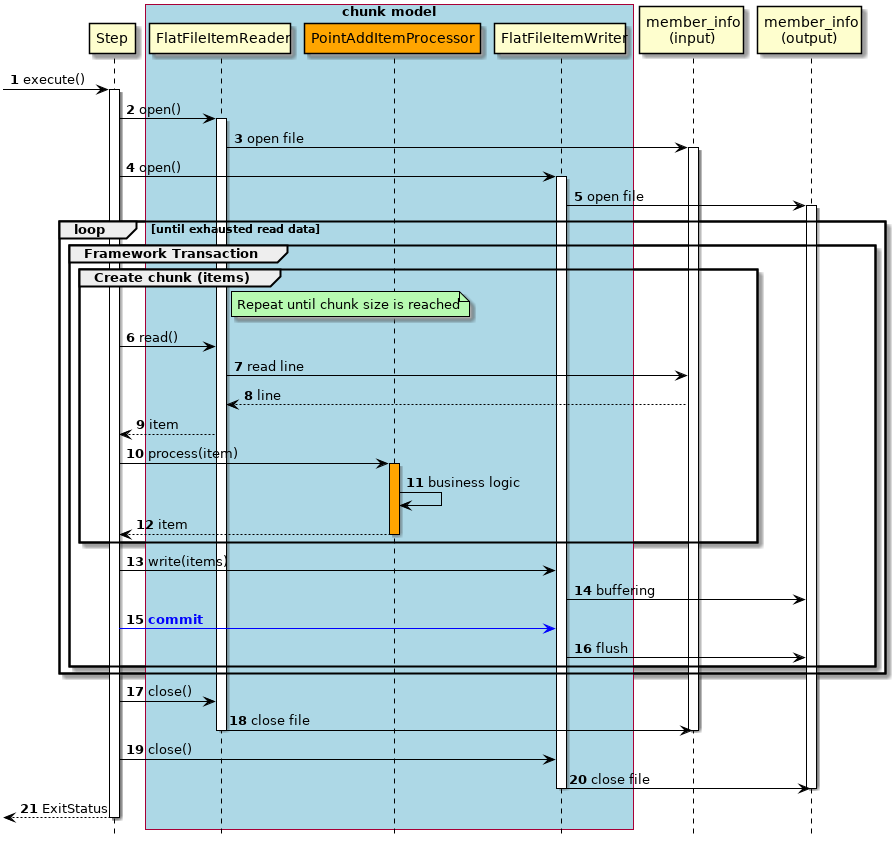
-
チャンクモデルの場合の処理シーケンスを説明する。
橙色のオブジェクトは今回実装するクラスを表す。
-
ジョブからステップが実行される。
-
ステップは、入力リソースをオープンする。
-
FlatFileItemReaderは、member_info(input)ファイルをオープンする。 -
ステップは、出力リソースをオープンする。
-
FlatFileItemWriterは、member_info(output)ファイルをオープンする。-
入力データがなくなるまで6から16の処理を繰り返す。
-
チャンク単位で、フレームワークトランザクション(擬似的)を開始する。
-
チャンクサイズに達するまで6から12までの処理を繰り返す。
-
-
ステップは、
FlatFileItemReaderから入力データを1レコード取得する。 -
FlatFileItemReaderは、member_info(input)ファイルから入力データを1レコード取得する。 -
member_info(input)ファイルは、
FlatFileItemReaderに入力データを返却する。 -
FlatFileItemReaderは、ステップに入力データを返却する。 -
ステップは、
PointAddItemProcessorで入力データに対して処理を行う。 -
PointAddItemProcessorは、入力データを読み込んでポイント加算処理を行う。 -
PointAddItemProcessorは、ステップに処理結果を返却する。 -
ステップは、チャンクサイズ分のデータを
FlatFileItemWriterで出力する。 -
FlatFileItemWriterは、処理結果をバッファリングする。 -
ステップは、フレームワークトランザクション(擬似的)をコミットする。
-
FlatFileItemWriterは、フラッシュしてバッファ内のデータをmember_info(output)ファイルに書き込む。 -
ステップは、入力リソースをクローズする。
-
FlatFileItemReaderは、member_info(input)ファイルをクローズする。 -
ステップは、出力リソースをクローズする。
-
FlatFileItemWriterは、member_info(output)ファイルをクローズする。 -
ステップはジョブに終了コード(ここでは正常終了:0)を返却する。
- タスクレットモデルの場合の処理シーケンス
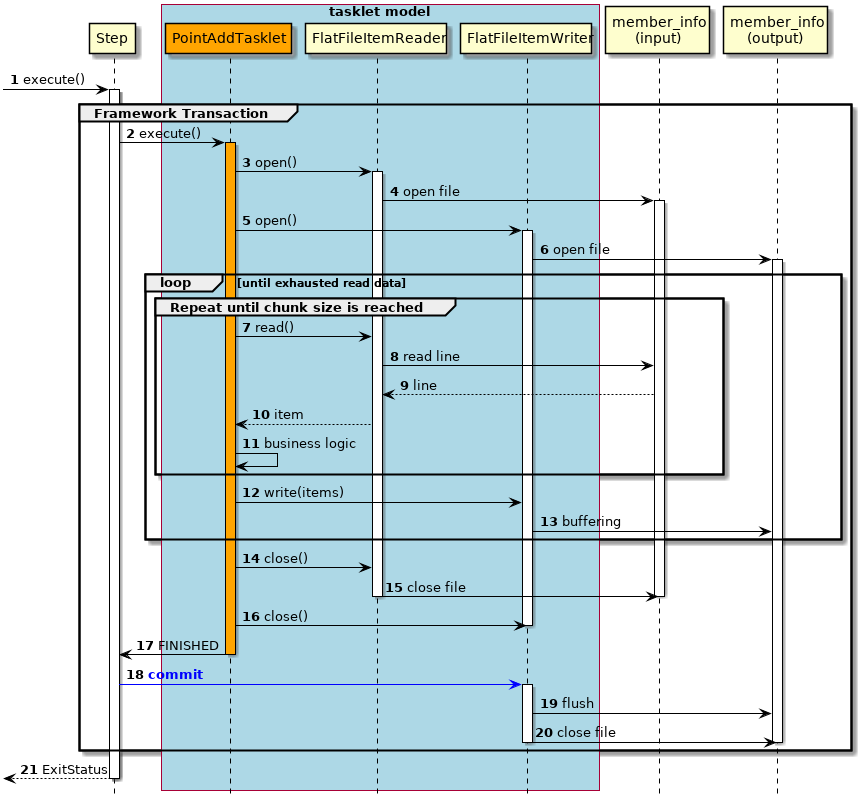
-
タスクレットモデルの場合の処理シーケンスについて説明する。
橙色のオブジェクトは今回実装するクラスを表す。
-
ジョブからステップが実行される。
-
ステップはフレームワークトランザクション(擬似的)を開始する。
-
-
ステップは
PointAddTaskletを実行する。 -
PointAddTaskletは、入力リソースをオープンする。 -
FlatFileItemReaderは、member_info(input)ファイルをオープンする。 -
PointAddTaskletは、出力リソースをオープンする。 -
FlatFileItemWriterは、member_info(output)ファイルをオープンする。-
入力データがなくなるまで7から13までの処理を繰り返す。
-
一定件数に達するまで7から11までの処理を繰り返す。
-
-
PointAddTaskletは、FlatFileItemReaderから入力データを1レコード取得する。 -
FlatFileItemReaderは、member_info(input)ファイルから入力データを1レコード取得する。 -
member_info(input)ファイルは、
FlatFileItemReaderに入力データを返却する。 -
FlatFileItemReaderは、タスクレットに入力データを返却する。 -
PointAddTaskletは、入力データを読み込んでポイント加算処理を行う。 -
PointAddTaskletは、一定件数分のデータをFlatFileItemWriterで出力する。 -
FlatFileItemWriterは、処理結果をバッファリングする。 -
PointAddTaskletは、入力リソースをクローズする。 -
FlatFileItemReaderは、member_info(input)ファイルをクローズする。 -
PointAddTaskletは、出力リソースをクローズする。 -
PointAddTaskletは、ステップへ処理終了を返却する。 -
ステップは、フレームワークトランザクション(擬似的)をコミットする。
-
FlatFileItemWriterは、フラッシュしてバッファ内のデータをmember_info(output)ファイルに書き込む。 -
FlatFileItemWriterは、member_info(output)ファイルをクローズする。 -
ステップはジョブに終了コード(ここでは正常終了:0)を返却する。
以降で、チャンクモデル、タスクレットモデルそれぞれの実装方法を説明する。
チャンクモデルでの実装
チャンクモデルでのファイルアクセスでデータ入出力を行うジョブの作成から実行までを以下の手順で実施する。
ジョブBean定義ファイルの作成
Bean定義ファイルにて、チャンクモデルでのファイルアクセスでデータ入出力を行うジョブを構成する要素の組み合わせ方を設定する。
ここでは、Bean定義ファイルの枠および共通的な設定のみ記述し、以降の項で各構成要素の設定を行う。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:p="http://www.springframework.org/schema/p"
xsi:schemaLocation="http://www.springframework.org/schema/beans https://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context https://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/batch https://www.springframework.org/schema/batch/spring-batch.xsd">
<!-- (1) -->
<import resource="classpath:META-INF/spring/job-base-context.xml"/>
<!-- (2) -->
<context:component-scan base-package="com.example.batch.tutorial.fileaccess.chunk"/>
</beans>| 項番 | 説明 |
|---|---|
(1) |
Macchinetta Batch 2.xを利用する際に、常に必要なBean定義を読み込む設定をインポートする。 |
(2) |
コンポーネントスキャン対象とするベースパッケージの設定を行う。 |
DTOの実装
業務データを保持するためのクラスとしてDTOクラスを実装する。
DTOクラスはファイルごとに作成する。
チャンクモデル/タスクレットモデルで共通して利用するため、既に作成している場合は読み飛ばしてよい。
以下のとおり、変換対象クラスとしてDTOクラスを実装する。
package com.example.batch.tutorial.common.dto;
public class MemberInfoDto {
private String id; // (1)
private String type; // (2)
private String status; // (3)
private int point; // (4)
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getType() {
return type;
}
public void setType(String type) {
this.type = type;
}
public String getStatus() {
return status;
}
public void setStatus(String status) {
this.status = status;
}
public int getPoint() {
return point;
}
public void setPoint(int point) {
this.point = point;
}
}| 項番 | 説明 |
|---|---|
(1) |
会員番号に対応するフィールドとして |
(2) |
会員種別に対応するフィールドとして |
(3) |
商品購入フラグに対応するフィールドとして |
(4) |
ポイントに対応するフィールドとして |
ファイルアクセスの定義
ファイルアクセスでデータ入出力するためのジョブBean定義ファイルの設定を行う。
ItemReader、ItemWriterの設定として、ジョブBean定義ファイルに以下の(1)以降を追記する。
ここで触れていない設定内容については、可変長レコードの入力
および可変長レコードの出力を参照。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:p="http://www.springframework.org/schema/p"
xsi:schemaLocation="http://www.springframework.org/schema/beans https://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context https://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/batch https://www.springframework.org/schema/batch/spring-batch.xsd">
<import resource="classpath:META-INF/spring/job-base-context.xml"/>
<context:component-scan base-package="com.example.batch.tutorial.fileaccess.chunk"/>
<!-- (1) (2) -->
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['inputFile']}"
p:encoding="UTF-8"
p:strict="true">
<property name="lineMapper">
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="lineTokenizer"> <!-- (3) -->
<bean class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"
p:names="id,type,status,point"
p:delimiter=","
p:quoteCharacter='"'/> <!-- (4) (5) -->
</property>
<property name="fieldSetMapper"> <!-- (6) -->
<bean class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"
p:targetType="com.example.batch.tutorial.common.dto.MemberInfoDto"/>
</property>
</bean>
</property>
</bean>
<!-- (7) (8) -->
<bean id="writer"
class="org.springframework.batch.item.file.FlatFileItemWriter" scope="step"
p:resource="file:#{jobParameters['outputFile']}"
p:encoding="UTF-8"
p:lineSeparator="
"
p:appendAllowed="false"
p:shouldDeleteIfExists="true"
p:transactional="true">
<property name="lineAggregator"> <!-- (9) -->
<bean class="org.springframework.batch.item.file.transform.DelimitedLineAggregator"
p:delimiter=","> <!-- (10) -->
<property name="fieldExtractor"> <!-- (11) -->
<bean class="org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor"
p:names="id,type,status,point"/> <!-- (12) -->
</property>
</bean>
</property>
</bean>
</beans>| 項番 | 説明 |
|---|---|
(1) |
ItemReaderの設定を行う。 |
(2) |
|
(3) |
lineTokenizerの設定を行う。 |
(4) |
|
(5) |
|
(6) |
|
(7) |
ItemWriterの設定を行う。 |
(8) |
|
(9) |
|
(10) |
|
(11) |
|
(12) |
|
|
擬似的トランザクション制御の有効
擬似的トランザクション制御を有効にすると、リソースへの書き込みを遅延し、コミットタイミングで実際に書き出す。 そのため、ファイルへの書き出しまでメモリ内に出力分のデータを保持することになり、取り扱うデータ量が多い場合、メモリ不足でエラーとなる可能性が高くなる。 このチュートリアルで実装するジョブは、取り扱うデータ量が少ないことから擬似的トランザクション制御を有効にしている。 詳細は、非トランザクショナルなデータソースに対する補足を参照。 |
ロジックの実装
ポイント加算処理を行うビジネスロジッククラスを実装する。
以下の作業を実施する。
PointAddItemProcessorクラスの実装
ItemProcessorインタフェースを実装したPointAddItemProcessorクラスを実装する。
package com.example.batch.tutorial.fileaccess.chunk;
import org.springframework.batch.item.ItemProcessor;
import org.springframework.stereotype.Component;
import com.example.batch.tutorial.common.dto.MemberInfoDto;
@Component // (1)
public class PointAddItemProcessor implements ItemProcessor<MemberInfoDto, MemberInfoDto> { // (2)
private static final String TARGET_STATUS = "1"; // (3)
private static final String INITIAL_STATUS = "0"; // (4)
private static final String GOLD_MEMBER = "G"; // (5)
private static final String NORMAL_MEMBER = "N"; // (6)
private static final int MAX_POINT = 1000000; // (7)
@Override
public MemberInfoDto process(MemberInfoDto item) throws Exception { // (8) (9) (10)
if (TARGET_STATUS.equals(item.getStatus())) {
if (GOLD_MEMBER.equals(item.getType())) {
item.setPoint(item.getPoint() + 100);
} else if (NORMAL_MEMBER.equals(item.getType())) {
item.setPoint(item.getPoint() + 10);
}
if (item.getPoint() > MAX_POINT) {
item.setPoint(MAX_POINT);
}
item.setStatus(INITIAL_STATUS);
}
return item;
}
}| 項番 | 説明 |
|---|---|
(1) |
コンポーネントスキャンの対象とするため、 |
(2) |
入出力で使用するオブジェクトの型をそれぞれ型引数に指定した |
(3) |
定数として、ポイント加算対象とする商品購入フラグ:1を定義する。 |
(4) |
定数として、商品購入フラグの初期値:0を定義する。 |
(5) |
定数として、会員区分:G(ゴールド会員)を定義する。 |
(6) |
定数として、会員区分:N(一般会員)を定義する。 |
(7) |
定数として、ポイントの上限値:1000000を定義する。 |
(8) |
商品購入フラグおよび、会員種別に応じてポイント加算するビジネスロジックを実装する。 |
(9) |
返り値の型は、このクラスで実装している |
(10) |
引数として受け取る |
ジョブBean定義ファイルの設定
作成したビジネスロジックをジョブとして設定するため、ジョブBean定義ファイルに以下の(1)以降を追記する。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:p="http://www.springframework.org/schema/p"
xsi:schemaLocation="http://www.springframework.org/schema/beans https://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context https://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/batch https://www.springframework.org/schema/batch/spring-batch.xsd">
<import resource="classpath:META-INF/spring/job-base-context.xml"/>
<context:component-scan base-package="com.example.batch.tutorial.fileaccess.chunk"/>
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['inputFile']}"
p:encoding="UTF-8"
p:strict="true">
<property name="lineMapper">
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="lineTokenizer">
<bean class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"
p:names="id,type,status,point"
p:delimiter=","
p:quoteCharacter='"'/>
</property>
<property name="fieldSetMapper">
<bean class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"
p:targetType="com.example.batch.tutorial.common.dto.MemberInfoDto"/>
</property>
</bean>
</property>
</bean>
<bean id="writer"
class="org.springframework.batch.item.file.FlatFileItemWriter" scope="step"
p:resource="file:#{jobParameters['outputFile']}"
p:encoding="UTF-8"
p:lineSeparator="
"
p:appendAllowed="false"
p:shouldDeleteIfExists="true"
p:transactional="true">
<property name="lineAggregator">
<bean class="org.springframework.batch.item.file.transform.DelimitedLineAggregator"
p:delimiter=",">
<property name="fieldExtractor">
<bean class="org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor"
p:names="id,type,status,point"/>
</property>
</bean>
</property>
</bean>
<!-- (1) -->
<batch:job id="jobPointAddChunk" job-repository="jobRepository">
<batch:step id="jobPointAddChunk.step01"> <!-- (2) -->
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="reader"
processor="pointAddItemProcessor"
writer="writer" commit-interval="10"/> <!-- (3) -->
</batch:tasklet>
</batch:step>
</batch:job>
</beans>| 項番 | 説明 |
|---|---|
(1) |
ジョブの設定を行う。 |
(2) |
ステップの設定を行う。 |
(3) |
チャンクモデルジョブの設定を行う。 |
|
commit-intervalのチューニング
commit-intervalはチャンクモデルジョブにおける、性能上のチューニングポイントである。 このチュートリアルでは10件としているが、利用できるマシンリソースやジョブの特性によって適切な件数は異なる。 複数のリソースにアクセスしてデータを加工するジョブであれば10件から100件程度で処理スループットが頭打ちになることもある。 一方、入出力リソースが1:1対応しておりデータを移し替える程度のジョブであれば5,000件や10,000件でも処理スループットが伸びることがある。 ジョブ実装時のcommit-intervalは100件程度で仮置きしておき、 その後に実施した性能測定の結果に応じてジョブごとにチューニングするとよい。 |
ジョブの実行と結果の確認
作成したジョブをSTS上で実行し、結果を確認する。
実行構成からジョブを実行
以下のとおり実行構成を作成し、ジョブを実行する。
実行構成の作成手順は動作確認を参照。
ここでは、正常系データを利用してジョブを実行する。
Argumentsタブに入出力ファイルのパラメータを引数として追加する。
- 実行構成の設定値
-
-
Name: 任意の名称(例: Run FileAccessJob for ChunkModel)
-
Mainタブ
-
Project:
macchinetta-batch-tutorial -
Main class:
org.springframework.batch.core.launch.support.CommandLineJobRunner
-
-
Argumentsタブ
-
Program arguments:
META-INF/jobs/fileaccess/jobPointAddChunk.xml jobPointAddChunk inputFile=files/input/input-member-info-data.csv outputFile=files/output/output-member-info-data.csv
-
-
コンソールログの確認
Console Viewを開き、以下の内容のログが出力されていることを確認する。
-
処理が完了(COMPLETED)し、例外が発生していないこと。
(.. omitted)
[2020/03/10 13:11:26] [main] [o.s.b.c.l.s.SimpleJobLauncher] [INFO ] Job: [FlowJob: [name=jobPointAddChunk]] launched with the following parameters: [{inputFile=files/input/input-member-info-data.csv, outputFile=files/output/output-member-info-data.csv, jsr_batch_run_id=116}]
[2020/03/10 13:11:26] [main] [o.s.b.c.j.SimpleStepHandler] [INFO ] Executing step: [jobPointAddChunk.step01]
[2020/03/10 13:11:26] [main] [o.s.b.c.s.AbstractStep] [INFO ] Step: [jobPointAddChunk.step01] executed in 388ms
[2020/03/10 13:11:26] [main] [o.s.b.c.l.s.SimpleJobLauncher] [INFO ] Job: [FlowJob: [name=jobPointAddChunk]] completed with the following parameters: [{inputFile=files/input/input-member-info-data.csv, outputFile=files/output/output-member-info-data.csv, jsr_batch_run_id=116}] and the following status: [COMPLETED] in 461ms終了コードの確認
終了コードにより、正常終了したことを確認する。
確認手順はジョブの実行と結果の確認を参照。
終了コード(exit value)が0(正常終了)となっていることを確認する。

会員情報ファイルの確認
会員情報ファイルの入出力内容を比較し、確認内容のとおりとなっていることを確認する。
- 確認内容
-
-
出力ディレクトリに会員情報ファイルが出力されていること
-
出力ファイル: files/output/output-member-info-data.csv
-
-
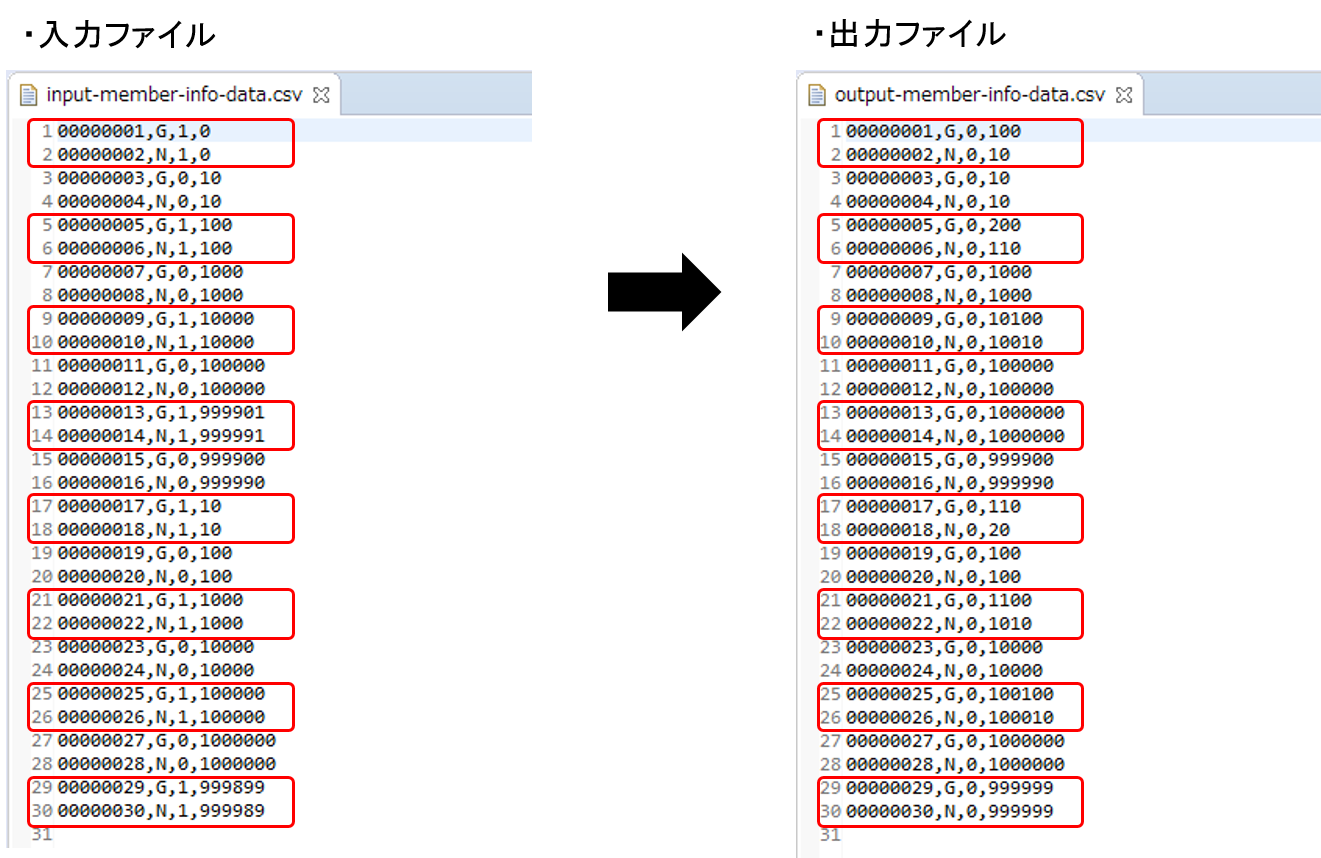
statusフィールド
-
"1"(処理対象)から"0"(初期状態)に更新されていること
-
-
pointフィールド
-
ポイント加算対象について、会員種別に応じたポイントが加算されていること
-
typeフィールドが"G"(ゴールド会員)の場合は100ポイント
-
typeフィールドが"N"(一般会員)の場合は10ポイント
-
-
1,000,000(上限値)を超えたレコードが存在しないこと
-
-
会員情報ファイルの入出力内容は以下のとおり。
ファイルのフィールドはid(会員番号)、type(会員種別)、status(商品購入フラグ)、point(ポイント)の順で出力される。
タスクレットモデルでの実装
タスクレットモデルでのファイルアクセスでデータ入出力を行うジョブの作成から実行までを以下の手順で実施する。
ジョブBean定義ファイルの作成
Bean定義ファイルにて、タスクレットモデルでのファイルアクセスでデータ入出力を行うジョブを構成する要素の組み合わせ方を設定する。
ここでは、Bean定義ファイルの枠および共通的な設定のみ記述し、以降の項で各構成要素の設定を行う。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:p="http://www.springframework.org/schema/p"
xsi:schemaLocation="http://www.springframework.org/schema/beans https://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context https://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/batch https://www.springframework.org/schema/batch/spring-batch.xsd">
<!-- (1) -->
<import resource="classpath:META-INF/spring/job-base-context.xml"/>
<!-- (2) -->
<context:component-scan base-package="com.example.batch.tutorial.fileaccess.tasklet"/>
</beans>| 項番 | 説明 |
|---|---|
(1) |
Macchinetta Batch 2.xを利用する際に、常に必要なBean定義を読み込む設定をインポートする。 |
(2) |
|
DTOの実装
業務データを保持するためのクラスとしてDTOクラスを実装する。
DTOクラスはファイルごとに作成する。
チャンクモデル/タスクレットモデルで共通して利用するため、既に作成している場合は読み飛ばしてよい。
以下のとおり、変換対象クラスとしてDTOクラスを実装する。
package com.example.batch.tutorial.common.dto;
public class MemberInfoDto {
private String id; // (1)
private String type; // (2)
private String status; // (3)
private int point; // (4)
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getType() {
return type;
}
public void setType(String type) {
this.type = type;
}
public String getStatus() {
return status;
}
public void setStatus(String status) {
this.status = status;
}
public int getPoint() {
return point;
}
public void setPoint(int point) {
this.point = point;
}
}| 項番 | 説明 |
|---|---|
(1) |
会員番号に対応するフィールドとして |
(2) |
会員種別に対応するフィールドとして |
(3) |
商品購入フラグに対応するフィールドとして |
(4) |
ポイントに対応するフィールドとして |
ファイルアクセスの定義
ファイルアクセスでデータ入出力するためのジョブBean定義ファイルの設定を行う。
ItemReader、ItemWriterの設定として、ジョブBean定義ファイルに以下の(1)以降を追記する。
ここで触れていない設定内容については、可変長レコードの入力
および可変長レコードの出力を参照。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:p="http://www.springframework.org/schema/p"
xsi:schemaLocation="http://www.springframework.org/schema/beans https://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context https://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/batch https://www.springframework.org/schema/batch/spring-batch.xsd">
<import resource="classpath:META-INF/spring/job-base-context.xml"/>
<context:component-scan base-package="com.example.batch.tutorial.fileaccess.tasklet"/>
<!-- (1) (2) -->
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['inputFile']}"
p:encoding="UTF-8"
p:strict="true">
<property name="lineMapper">
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="lineTokenizer"> <!-- (3) -->
<bean class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"
p:names="id,type,status,point"
p:delimiter=","
p:quoteCharacter='"'/> <!-- (4) (5) -->
</property>
<property name="fieldSetMapper"> <!-- (6) -->
<bean class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"
p:targetType="com.example.batch.tutorial.common.dto.MemberInfoDto"/>
</property>
</bean>
</property>
</bean>
<!-- (7) (8) -->
<bean id="writer"
class="org.springframework.batch.item.file.FlatFileItemWriter" scope="step"
p:resource="file:#{jobParameters['outputFile']}"
p:encoding="UTF-8"
p:lineSeparator="
"
p:appendAllowed="false"
p:shouldDeleteIfExists="true"
p:transactional="true">
<property name="lineAggregator"> <!-- (9) -->
<bean class="org.springframework.batch.item.file.transform.DelimitedLineAggregator"
p:delimiter=","> <!-- (10) -->
<property name="fieldExtractor"> <!-- (11) -->
<bean class="org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor"
p:names="id,type,status,point"/> <!-- (12) -->
</property>
</bean>
</property>
</bean>
</beans>| 項番 | 説明 |
|---|---|
(1) |
ItemReaderの設定を行う。 |
(2) |
|
(3) |
lineTokenizerの設定を行う。 |
(4) |
|
(5) |
|
(6) |
|
(7) |
ItemWriterの設定を行う。 |
(8) |
|
(9) |
|
(10) |
|
(11) |
|
(12) |
|
|
チャンクモデルのコンポーネントを利用するTasklet実装
このチュートリアルでは、タスクレットモデルでファイルアクセスするジョブの作成を容易に実現するために、 チャンクモデルのコンポーネントであるItemReader・ItemWriterを利用している。 Tasklet実装の中でチャンクモデルの各種コンポーネントを利用するかどうかは、 チャンクモデルのコンポーネントを利用するTasklet実装を参照して適宜判断してほしい。 ただし、タスクレットモデルでファイルアクセスする場合はItemReader・ItemWriterの実装クラスを利用するとよい。 |
ロジックの実装
ポイント加算処理を行うビジネスロジッククラスを実装する。
以下の作業を実施する。
PointAddTaskletクラスの実装
Taskletインタフェースを実装したPointAddTaskletクラスを作成する。
package com.example.batch.tutorial.fileaccess.tasklet;
import org.springframework.batch.core.StepContribution;
import org.springframework.batch.core.scope.context.ChunkContext;
import org.springframework.batch.core.step.tasklet.Tasklet;
import org.springframework.batch.item.ItemStreamException;
import org.springframework.batch.item.ItemStreamReader;
import org.springframework.batch.item.ItemStreamWriter;
import org.springframework.batch.repeat.RepeatStatus;
import org.springframework.context.annotation.Scope;
import org.springframework.stereotype.Component;
import com.example.batch.tutorial.common.dto.MemberInfoDto;
import javax.inject.Inject;
import java.util.ArrayList;
import java.util.List;
@Component // (1)
@Scope("step") // (2)
public class PointAddTasklet implements Tasklet {
private static final String TARGET_STATUS = "1"; // (3)
private static final String INITIAL_STATUS = "0"; // (4)
private static final String GOLD_MEMBER = "G"; // (5)
private static final String NORMAL_MEMBER = "N"; // (6)
private static final int MAX_POINT = 1000000; // (7)
private static final int CHUNK_SIZE = 10; // (8)
@Inject // (9)
ItemStreamReader<MemberInfoDto> reader; // (10)
@Inject // (9)
ItemStreamWriter<MemberInfoDto> writer; // (11)
@Override
public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception { // (12)
MemberInfoDto item = null;
List<MemberInfoDto> items = new ArrayList<>(CHUNK_SIZE); // (13)
try {
reader.open(chunkContext.getStepContext().getStepExecution().getExecutionContext()); // (14)
writer.open(chunkContext.getStepContext().getStepExecution().getExecutionContext()); // (14)
while ((item = reader.read()) != null) { // (15)
if (TARGET_STATUS.equals(item.getStatus())) {
if (GOLD_MEMBER.equals(item.getType())) {
item.setPoint(item.getPoint() + 100);
} else if (NORMAL_MEMBER.equals(item.getType())) {
item.setPoint(item.getPoint() + 10);
}
if (item.getPoint() > MAX_POINT) {
item.setPoint(MAX_POINT);
}
item.setStatus(INITIAL_STATUS);
}
items.add(item);
if (items.size() == CHUNK_SIZE) { // (16)
writer.write(items); // (17)
items.clear();
}
}
writer.write(items); // (18)
} finally {
try {
reader.close(); // (19)
} catch (ItemStreamException e) {
// do nothing.
}
try {
writer.close(); // (19)
} catch (ItemStreamException e) {
// do nothing.
}
}
return RepeatStatus.FINISHED; // (20)
}
}| 項番 | 説明 |
|---|---|
(1) |
コンポーネントスキャンの対象とするため、 |
(2) |
クラスに@Scopeアノテーションを付与して |
(3) |
定数として、ポイント加算対象とする商品購入フラグ:1を定義する。 |
(4) |
定数として、商品購入フラグの初期値:0を定義する。 |
(5) |
定数として、会員種別:G(ゴールド会員)を定義する。 |
(6) |
定数として、会員種別:N(一般会員)を定義する。 |
(7) |
定数として、ポイントの上限値:1000000を定義する。 |
(8) |
定数として、まとめて処理する単位(一定件数):10を定義する。 |
(9) |
|
(10) |
ファイルアクセスするために |
(11) |
ファイルアクセスするために |
(12) |
商品購入フラグおよび、会員種別に応じてポイント加算するビジネスロジックを実装する。 |
(13) |
一定件数分の |
(14) |
入出力リソースをオープンする。 |
(15) |
入力リソース全件を逐次ループ処理する。 |
(16) |
リストに追加した |
(17) |
処理したデータをファイルへ出力する。 |
(18) |
全体の処理件数/一定件数の余り分をファイルへ出力する。 |
(19) |
入出力リソースをクローズする。 |
(20) |
Taskletの処理が完了したかどうかを返却する。 |
ジョブBean定義ファイルの設定
作成したビジネスロジックをジョブとして設定するため、ジョブBean定義ファイルに以下の(1)以降を追記する。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:p="http://www.springframework.org/schema/p"
xsi:schemaLocation="http://www.springframework.org/schema/beans https://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context https://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/batch https://www.springframework.org/schema/batch/spring-batch.xsd">
<import resource="classpath:META-INF/spring/job-base-context.xml"/>
<context:component-scan base-package="com.example.batch.tutorial.fileaccess.tasklet"/>
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['inputFile']}"
p:encoding="UTF-8"
p:strict="true">
<property name="lineMapper">
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="lineTokenizer">
<bean class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"
p:names="id,type,status,point"
p:delimiter=","
p:quoteCharacter='"'/>
</property>
<property name="fieldSetMapper">
<bean class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"
p:targetType="com.example.batch.tutorial.common.dto.MemberInfoDto"/>
</property>
</bean>
</property>
</bean>
<bean id="writer"
class="org.springframework.batch.item.file.FlatFileItemWriter" scope="step"
p:resource="file:#{jobParameters['outputFile']}"
p:encoding="UTF-8"
p:lineSeparator="
"
p:appendAllowed="false"
p:shouldDeleteIfExists="true"
p:transactional="true">
<property name="lineAggregator">
<bean class="org.springframework.batch.item.file.transform.DelimitedLineAggregator"
p:delimiter=",">
<property name="fieldExtractor">
<bean class="org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor"
p:names="id,type,status,point"/>
</property>
</bean>
</property>
</bean>
<!-- (1) -->
<batch:job id="jobPointAddTasklet" job-repository="jobRepository">
<batch:step id="jobPointAddTasklet.step01"> <!-- (2) -->
<batch:tasklet transaction-manager="jobTransactionManager"
ref="pointAddTasklet"/> <!-- (3) -->
</batch:step>
</batch:job>
</beans>| 項番 | 説明 |
|---|---|
(1) |
ジョブの設定を行う。 |
(2) |
ステップの設定を行う。 |
(3) |
タスクレットの設定を行う。 |
ジョブの実行と結果の確認
作成したジョブをSTS上で実行し、結果を確認する。
実行構成からジョブを実行
以下のとおり実行構成を作成し、ジョブを実行する。
実行構成の作成手順は動作確認を参照。
ここでは、正常系データを利用してジョブを実行する。
Argumentsタブに入出力ファイルのパラメータを引数として追加する。
- 実行構成の設定値
-
-
Name: 任意の名称(例: Run FileAccessJob for TaskletModel)
-
Mainタブ
-
Project:
macchinetta-batch-tutorial -
Main class:
org.springframework.batch.core.launch.support.CommandLineJobRunner
-
-
Argumentsタブ
-
Program arguments:
META-INF/jobs/fileaccess/jobPointAddTasklet.xml jobPointAddTasklet inputFile=files/input/input-member-info-data.csv outputFile=files/output/output-member-info-data.csv
-
-
コンソールログの確認
Console Viewを開き、以下の内容のログが出力されていることを確認する。
-
処理が完了(COMPLETED)し、例外が発生していないこと。
(.. omitted)
[2020/03/10 13:18:03] [main] [o.s.b.c.l.s.SimpleJobLauncher] [INFO ] Job: [FlowJob: [name=jobPointAddTasklet]] launched with the following parameters: [{inputFile=files/input/input-member-info-data.csv, outputFile=files/output/output-member-info-data.csv, jsr_batch_run_id=118}]
[2020/03/10 13:18:03] [main] [o.s.b.c.j.SimpleStepHandler] [INFO ] Executing step: [jobPointAddTasklet.step01]
[2020/03/10 13:18:03] [main] [o.s.b.c.s.AbstractStep] [INFO ] Step: [jobPointAddTasklet.step01] executed in 161ms
[2020/03/10 13:18:03] [main] [o.s.b.c.l.s.SimpleJobLauncher] [INFO ] Job: [FlowJob: [name=jobPointAddTasklet]] completed with the following parameters: [{inputFile=files/input/input-member-info-data.csv, outputFile=files/output/output-member-info-data.csv, jsr_batch_run_id=118}] and the following status: [COMPLETED] in 229ms終了コードの確認
終了コードにより、正常終了したことを確認する。
確認手順はジョブの実行と結果の確認を参照。
終了コード(exit value)が0(正常終了)となっていることを確認する。

会員情報ファイルの確認
会員情報ファイルの入出力内容を比較し、確認内容のとおりとなっていることを確認する。
- 確認内容
-
-
出力ディレクトリに会員情報ファイルが出力されていること
-
出力ファイル: files/output/output-member-info-data.csv
-
-
statusフィールド
-
"1"(処理対象)から"0"(初期状態)に更新されていること
-
-
pointフィールド
-
ポイント加算対象について、会員種別に応じたポイントが加算されていること
-
typeフィールドが"G"(ゴールド会員)の場合は100ポイント
-
typeフィールドが"N"(一般会員)の場合は10ポイント
-
-
1,000,000(上限値)を超えたレコードが存在しないこと
-
-
会員情報ファイルの入出力内容は以下のとおり。
ファイルのフィールドはid(会員番号)、type(会員種別)、status(商品購入フラグ)、point(ポイント)の順で出力される。