5.4.4. インターネットストレージ内ファイルの効率的な検索¶
目次
5.4.4.1. Overview¶
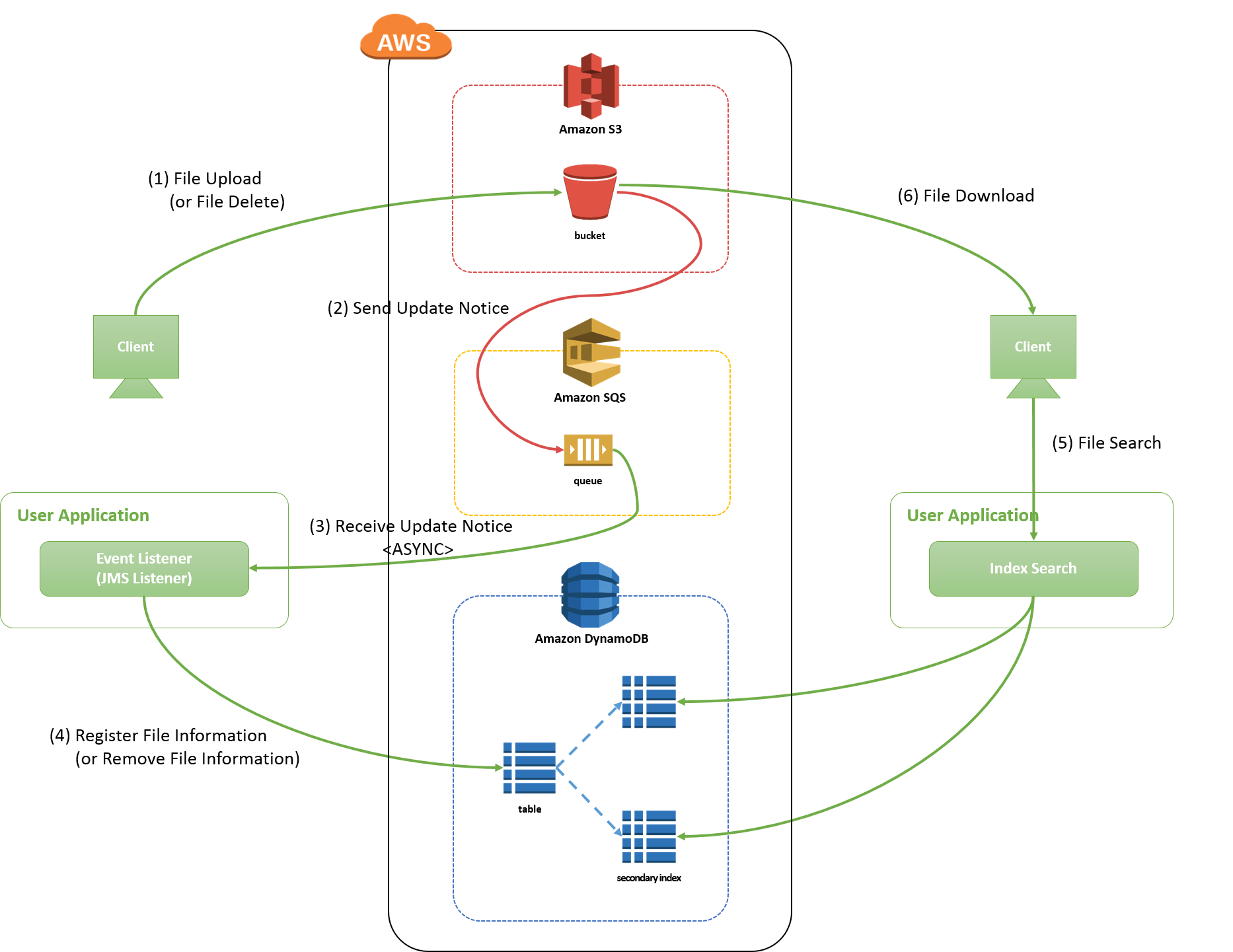
項番 説明
5.4.4.1.1. Amazon S3のイベント通知機能¶
5.4.4.1.2. メタデータの格納先¶
Note
DynamoDBに登録する検索情報は、情報量が多くなることにより検索性能にも影響が出るため、実現したい「高度な検索」の要件に応じた登録情報を検討し、不必要な情報は登録しないようにすることが望ましい。
Note
本ガイドラインではメタデータの登録先にDynamoDBを使用しているが、登録先は検索要件に応じて選択することができる。 詳細は メタデータの登録先について を参照されたい。
Note
本ガイドラインでは検索用情報としてイベントメッセージから取得できる情報のみを登録しているが、検索要件に応じてイベントメッセージに含まれない情報も別途取得して登録することができる。 詳細は メタデータの登録項目について を参照されたい。
5.4.4.2. How to use¶
5.4.4.2.1. ライブラリの使い分け¶
CrudRepositoryインターフェースにより、Spring Data と親和性のあるリソースアクセスの抽象化が可能である。DynamoDBMapperを利用することにより、参照・更新の都度DynamoDBMapperConfig.ConsistentReads、DynamoDBMapperConfig.SaveBehaviorによるきめ細かいオプションを指定することができる。5.4.4.2.2. Amazon S3の設定¶
5.4.4.2.2.1. SQSへのS3イベントの通知¶
ObjectCreate (All)のイベント設定によって登録、更新のイベント通知がまとめて設定される。| 名前 | イベント | プレフィックス | サフィックス | 送信先 | SQS |
|---|---|---|---|---|---|
| Create ※任意 | ObjectCreate (All) | - | - | SQSキュー | イベント通知先として作成したSQSキュー |
| Delete ※任意 | ObjectDelete (All) | - | - | SQSキュー | イベント通知先として作成したSQSキュー |
5.4.4.2.3. Amazon DynamoDBの設定¶
5.4.4.2.3.1. テーブルおよびセカンダリインデックスの作成¶
FileMetaDataテーブルを以下の構成で作成する。| PK | 属性名(論理) | 属性名(物理) | 登録値サンプル | 属性説明 |
|---|---|---|---|---|
| パーティションキー | オブジェクトキー | objectKey |
USER001_FILE001.txt | ファイルを一意に特定するためのキー。ユーザIDとファイル名の連結値を登録する。 |
| - | バケット名 | bucketName |
fileupload.a | ファイルアップロード先のバケット名 |
| - | ファイルID | fileId |
FILE001.txt | ファイルID |
| - | サイズ | size |
12 | ファイルサイズ |
| - | 登録ユーザ | uploadUser |
USER001 | ファイルアップロードを行ったユーザ名 |
| - | 登録日付 | uploadDate |
2017-08-20 | ファイルアップロードを行った日付 |
| - | シーケンサ | sequencer |
00599E9964323435D9 | 同一ファイルをアップロードした際の順序性検証のために使用する。 詳細は メタデータの登録 を参照されたい。 |
| 検索条件 | セカンダリインデックス名 | パーティションキー | ソートキー | 種類 |
|---|---|---|---|---|
| 特定ユーザのファイルを更新日時順に取得する。 | uploadUser-uploadDate-index |
登録ユーザ | 登録日付 | グローバルセカンダリインデックス |
| 特定バケットのファイルサイズ順に取得する。 | bucketName-size-index |
バケット名 | サイズ | グローバルセカンダリインデックス |
5.4.4.2.4. メッセージの非同期受信¶
5.4.4.2.4.1. S3イベントメッセージの受信¶
SQSキューに通知されるS3のイベントメッセージを受信する。 非同期処理の実装(共通編) に従って、SQSキューからイベントメッセージを受信するリスナークラスを作成する。
リスナークラスではイベントメッセージの受信と同時に後述するメタデータの登録も行うため、実装例は メタデータの登録 を参照されたい。
5.4.4.2.5. メタデータの登録¶
sequencerの値を比較することで行う。sequencerを利用したイベントの順序性の検証についての詳細は イベントメッセージの構造 を参照されたい。pom.xml... <!-- (1) --> <dependency> <groupId>com.amazonaws</groupId> <artifactId>aws-java-sdk-dynamodb</artifactId> </dependency> ...
項番 説明 (1)AWS SDK for Java を利用するためのaws-java-sdk-dynamodbを定義する。
xxx-env.xml<!-- Spring Data DynamoDB --> <!-- (1) --> <bean id="amazonDynamoDB" class="com.example.xxx.app.fileupload.DynamoDBClientFactory" factory-method="create"> <constructor-arg index="0" value="${cloud.aws.region.static}" /> </bean> <!-- (2) --> <bean id="dynamoDBMapper" class="com.amazonaws.services.dynamodbv2.datamodeling.DynamoDBMapper"> <constructor-arg index="0" ref="amazonDynamoDB" /> </bean>
項番 説明 (1)DynamoDBへアクセスするためのAmazonDynamoDBClientを定義する。DynamoDBClientFactoryを使用してインスタンスを生成する。(2)AWS SDK for Java を利用するためのDynamoDBMapperを定義する。
DynamoDBClientFactory.javapublic class DynamoDBClientFactory { public static AmazonDynamoDB create(String region) { // (1) return AmazonDynamoDBClientBuilder.standard().withRegion(region).build(); } }
項番 説明 (1)AmazonDynamoDBClientBuilderを使用してインスタンスを生成する。
S3NoticeMessageListener.java@Component public class S3NoticeMessageListener { @Inject DynamoDBMapper dbMapper; // (1) private static final String EV_CREATED = "ObjectCreated"; private static final String EV_REMOVED = "ObjectRemoved"; @JmsListener(destination = "S3_UPDATE_NOTICE", concurrency = "1") // (2) public void receive(SQSTextMessage recvMsg) { try { // (3) JSON -> Java S3EventNotification event = S3EventNotification.parseJson(recvMsg.getText()); S3EventNotificationRecord eventMsg = event.getRecords().get(0); // Consistent Read FileMetaData currentData = dbMapper.load(FileMetaData.class, eventMsg.getS3().getObject().getKey(), ConsistentReads.CONSISTENT.config()); // (4) // Create if (currentData == null) { createRecord(eventMsg); // (5) // Update } else { updateRecord(currentData, eventMsg); // (8) } } catch (JMSException e) { // omitted } } private void createRecord(S3EventNotificationRecord eventMsg) { String objectKey = eventMsg.getS3().getObject().getKey(); // omitted // objectKey -> {userId, fileName} String[] objectKeyArr = dataSplit(objectKey); // (6) // create if (eventMsg.getEventName().contains(EV_CREATED)) { FileMetaData newData = new FileMetaData(); newData.setObjectKey(objectKey); // omitted dbMapper.save(newData, SaveBehavior.CLOBBER.config()); // (7) } } private void updateRecord(FileMetaData currentData, S3EventNotificationRecord eventMsg) { // event sequence check String sequencer = eventMsg.getS3().getObject().getSequencer(); if (!isNewEntry(currentData.getSequencer(), sequencer)) { // (9) return; } String objectKey = eventMsg.getS3().getObject().getKey(); // omitted // objectKey -> {userId, fileName} String[] objectKeyArr = dataSplit(objectKey); try { // update if (eventMsg.getEventName().contains(EV_CREATED)) { currentData.setBucketName(bucketName); // omitted dbMapper.save(currentData, SaveBehavior.UPDATE.config()); // (10) // delete } else if (eventMsg.getEventName().contains(EV_REMOVED)) { dbMapper.delete(currentData, SaveBehavior.UPDATE.config()); // (11) } } catch (ConditionalCheckFailedException e) { // (12) // get current data currentData = dbMapper.load(FileMetaData.class, eventMsg.getS3().getObject().getKey(), ConsistentReads.CONSISTENT.config()); // update retry updateRecord(currentData, eventMsg); } } private boolean isNewEntry(String curSequencer, String newSequencer) { int len = Math.abs(curSequencer.length() - newSequencer.length()); if (len > 0) { String paddingStr = String.format("%0"+ len +"d", 0); if (curSequencer.length() < newSequencer.length()) { curSequencer += paddingStr; } else if (newSequencer.length() < curSequencer.length()) { newSequencer += paddingStr; } } return newSequencer.compareTo(curSequencer) > 0; } private String[] dataSplit(String objectKey) { // input string is "[UserID]-[FileName]" // omitted return new String[]{userId, fileName}; } }
| 項番 | 説明 |
|---|---|
(1)
|
AWS SDK for Java を利用するための
DynamoDBMapperを設定する。 |
(2)
|
非同期受信用のメソッドに対し
@JmsListenerアノテーションを設定する。destination属性には、受信先のキュー名を指定する。concurrency属性には、リスナーメソッドの並列数の上限を指定する。DynamoDBに登録済の既存データを検索する処理とそのデータの更新処理までの一連を排他的に実行したいため、並列数の上限を
1に設定する。 |
(3)
|
S3EventNotification#parseJsonを利用したJSON->Java変換を実行する。 |
(4)
|
プライマリキーを指定して既存データを検索する。
読み込み整合性に「強力な整合性のある読み込み(
ConsistentReads.CONSISTENT)」を指定し、最新状態の既存データを確実に取得する。 |
(5)
|
既存データが未登録の場合は、新規登録を行う。
|
(6)
|
オブジェクトキーを分解して「ユーザID」、「ファイル名」を取得する。
|
(7)
|
DynamoDBへの登録を実行する。新規登録のため、
SaveBehavior.CLOBBERを指定する。(既存データが未登録であることを確認しているため効果はないが、
SaveBehavior.CLOBBERを指定することで既存データの全ての属性をクリアした後に登録データの値で置換される。) |
(8)
|
既存データが登録済の場合は、更新または削除を行う。
|
(9)
|
イベントメッセージの順序性を保障するため、既存データが登録データよりも過去に発生したイベントによって登録されたものであることを確認する。
|
(10)
|
DynamoDBへの更新を実行する。既存データの更新のため、
SaveBehavior.UPDATEを指定する。SaveBehavior.UPDATEを指定することで、登録データにフィールドとして存在する属性のみが更新される。(フィールドがnull値の場合も更新対象となる)また、後述する「バージョン番号を使用したオプティミスティックロック」も利用可能となる。
|
(11)
|
DynamoDBからの削除を実行する。
更新時と同様、後述する「バージョン番号を使用したオプティミスティックロック」を利用するため
SaveBehavior.UPDATEを指定する。 |
(12)
|
バージョンチェックエラーが発生した場合(既存データに別の更新がされていた場合)は既存データを再取得して更新処理を再実行する。
再実行の結果、(9)の処理にて既存データよりも今回の登録データの方が新しい情報である場合は更新処理を実行し、そうでない場合は更新不要と判定する。
|
FileMetaDataテーブルの項目のマッピングクラスの実装例を以下に示す。FileMetaData.java@DynamoDBTable(tableName = "FileMetaData") // (1) public class FileMetaData { private String objectKey; private String bucketName; private String fileName; private int size; private String uploadUser; private String uploadDate; private String sequencer; private Long version; @DynamoDBHashKey // (2) public String getObjectKey() { return objectKey; } // omitted @DynamoDBIndexHashKey(globalSecondaryIndexName = "bucketName-size-index") // (3) public String getBucketName() { return bucketName; } // omitted @DynamoDBAttribute // (8) public String getFileName() { return fileName; } // omitted @DynamoDBIndexRangeKey(globalSecondaryIndexName = "bucketName-size-index") // (4) public int getSize() { return size; } // omitted @DynamoDBIndexHashKey(globalSecondaryIndexName = "uploadUser-uploadDate-index") // (5) public String getUploadUser() { return uploadUser; } // omitted @DynamoDBIndexRangeKey(globalSecondaryIndexName = "uploadUser-uploadDate-index") // (6) public String getUploadDate() { return uploadDate; } // omitted @DynamoDBAttribute public String getSequencer() { return sequencer; } // omitted @DynamoDBVersionAttribute // (7) public Long getVersion() { return version; } // omitted }
| 項番 | 説明 |
|---|---|
(1)
|
クラスに対して
@DynamoDBTableアノテーションを付与し、tableNameにマッピング対象となるFileMetaDataテーブルを指定する。 |
(2)
|
FileMetaDataテーブルのハッシュキーであるobjectKeyのGetterに対して@DynamoDBHashKeyアノテーションを付与する。 |
(3)
|
グローバルセカンダリインデックス「
bucketName-size-index」のハッシュキーであるbucketNameのGetterに対して@DynamoDBIndexHashKeyアノテーションを付与する。globalSecondaryIndexNameにはbucketName-size-indexを指定する。 |
(4)
|
グローバルセカンダリインデックス「
bucketName-size-index」のソートキーであるsizeのGetterに対して@DynamoDBIndexRangeKeyアノテーションを付与する。globalSecondaryIndexNameにはbucketName-size-indexを指定する。 |
(5)
|
グローバルセカンダリインデックス「
uploadUser-uploadDate-index」のハッシュキーであるuploadUserのGetterに対して@DynamoDBIndexHashKeyアノテーションを付与する。globalSecondaryIndexNameにはuploadUser-uploadDate-indexを指定する。 |
(6)
|
グローバルセカンダリインデックス「
uploadUser-uploadDate-index」のソートキーであるuploadDateのGetterに対して@DynamoDBIndexRangeKeyアノテーションを付与する。globalSecondaryIndexNameにはuploadUser-uploadDate-indexを指定する。 |
(7)
|
バージョン番号を使用したオプティミスティックロックを行うため、
versionのGetterに対して@DynamoDBVersionAttributeアノテーションを付与する。 |
(8)
|
プライマリキーまたはセカンダリインデックスに使用しない属性については、
@DynamoDBAttributeアノテーションを付与する。 |
5.4.4.2.6. オブジェクトの検索¶
プライマリキーまたはセカンダリインデックスを使用してDynamoDBからアップロードファイルのメタデータを検索する。
以下の条件指定による検索を行う。
- ハッシュキー(オブジェクトキー)を指定して単一のアップロード情報を取得する。
- グローバルセカンダリインデックス(登録ユーザ、登録日時)を指定して、特定ユーザの特定日のアップロードファイル情報をリスト取得する。
- グローバルセカンダリインデックスのハッシュキーのみ(登録ユーザ)を指定して、特定ユーザのアップロードファイル情報を登録日順(昇順)にリスト取得する。
- グローバルセカンダリインデックスのハッシュキーのみ(バケット名)を指定して、特定バケットのアップロードファイル情報をサイズ順(降順)にリスト取得する。
検索処理の実装例を以下に示す。
SearchSharedServiceImpl.java@Service public class SearchSharedServiceImpl implements SearchSharedService { @Inject DynamoDBMapper dbMapper; // (1) public FileMetaData doPkSearch(String objectKey) { // (2) FileMetaData result = dbMapper.load(FileMetaData.class, objectKey); return result; } public List<FileMetaData> doUserIdIndexSearch(String uploadUser, String uploadDate) { HashMap<String, AttributeValue> eav = new HashMap<>(); eav.put(":v1", new AttributeValue().withS(uploadUser)); String keyConditionExpression = "uploadUser = :v1"; if (uploadDate.length() > 0) { eav.put(":v2", new AttributeValue().withS(uploadDate)); keyConditionExpression += " and uploadDate = :v2"; } // (3) DynamoDBQueryExpression<FileMetaData> queryExpression = new DynamoDBQueryExpression<FileMetaData>() .withIndexName("uploadUser-uploadDate-index") .withConsistentRead(false) .withKeyConditionExpression(keyConditionExpression) .withExpressionAttributeValues(eav); List<FileMetaData> indexResult = dbMapper.query(FileMetaData.class, queryExpression); return indexResult; } public List<FileMetaData> doBucketNameIndexSearch(String bucketName) { HashMap<String, AttributeValue> eav = new HashMap<>(); eav.put(":v1", new AttributeValue().withS(bucketName)); // (4) DynamoDBQueryExpression<FileMetaData> queryExpression = new DynamoDBQueryExpression<FileMetaData>() .withIndexName("bucketName-size-index") .withConsistentRead(false) .withKeyConditionExpression("bucketName = :v1") .withScanIndexForward(false) .withExpressionAttributeValues(eav); List<FileMetaData> indexResult = dbMapper.query(FileMetaData.class, queryExpression); return indexResult; } }
| 項番 | 説明 |
|---|---|
(1)
|
AWS SDK for Java を利用するための
DynamoDBMapperを設定する。 |
(2)
|
FileMetaDataテーブルのハッシュキーであるobjectKeyを指定した検索を実行する。プライマリキーを指定した検索となるため、1項目のみ取得される。
|
(3)
|
グローバルセカンダリインデックス「
uploadUser-uploadDate-index」を指定した検索を実行する。ハッシュキーが
uploadUser、ソートキーがuploadDateとなる。uploadUserのみが指定された場合は、uploadUserが一致する項目がuploadDate順(昇順)にリスト取得される。uploadUserとuploadDateの両方が指定された場合は、uploadUserとuploadDateが一致する項目がリスト取得される。 |
(4)
|
グローバルセカンダリインデックス「
bucketName-size-index」を指定した検索を実行する。ハッシュキーが
bucketName、ソートキーがsizeとなる。bucketNameが一致する項目がsize順(降順)にリスト取得される。 |