7.7. Beanマッピング(Dozer)¶
7.7.1. Overview¶
Beanマッピングは、一つのBeanを他のBeanにフィールド値をコピーすることである。
AccountFormオブジェクトを、ドメイン層のAccountオブジェクトに変換する場合を考える。AccountFormオブジェクトを、AccountオブジェクトにBeanマッピングし、ドメイン層では、Accountオブジェクトを使用する。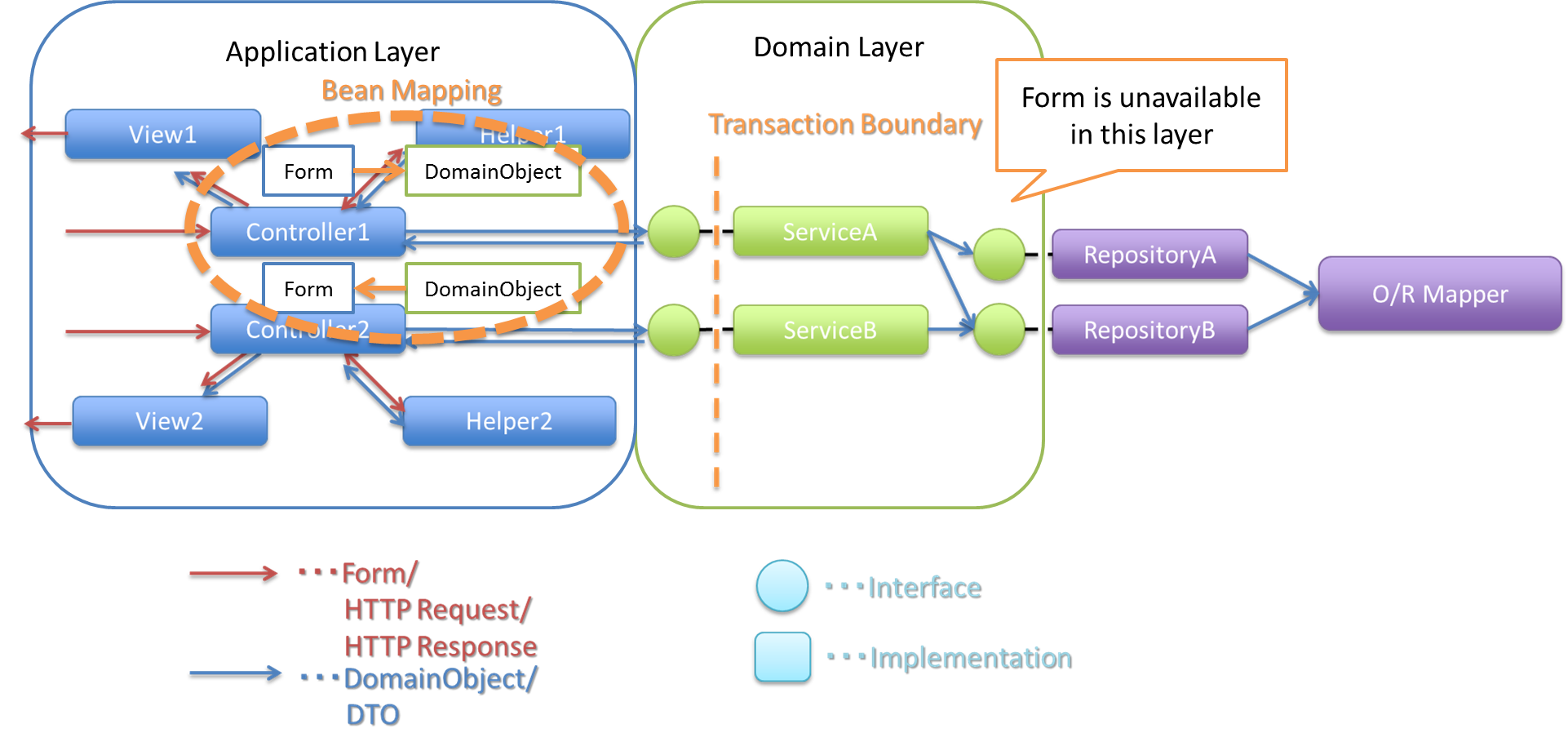
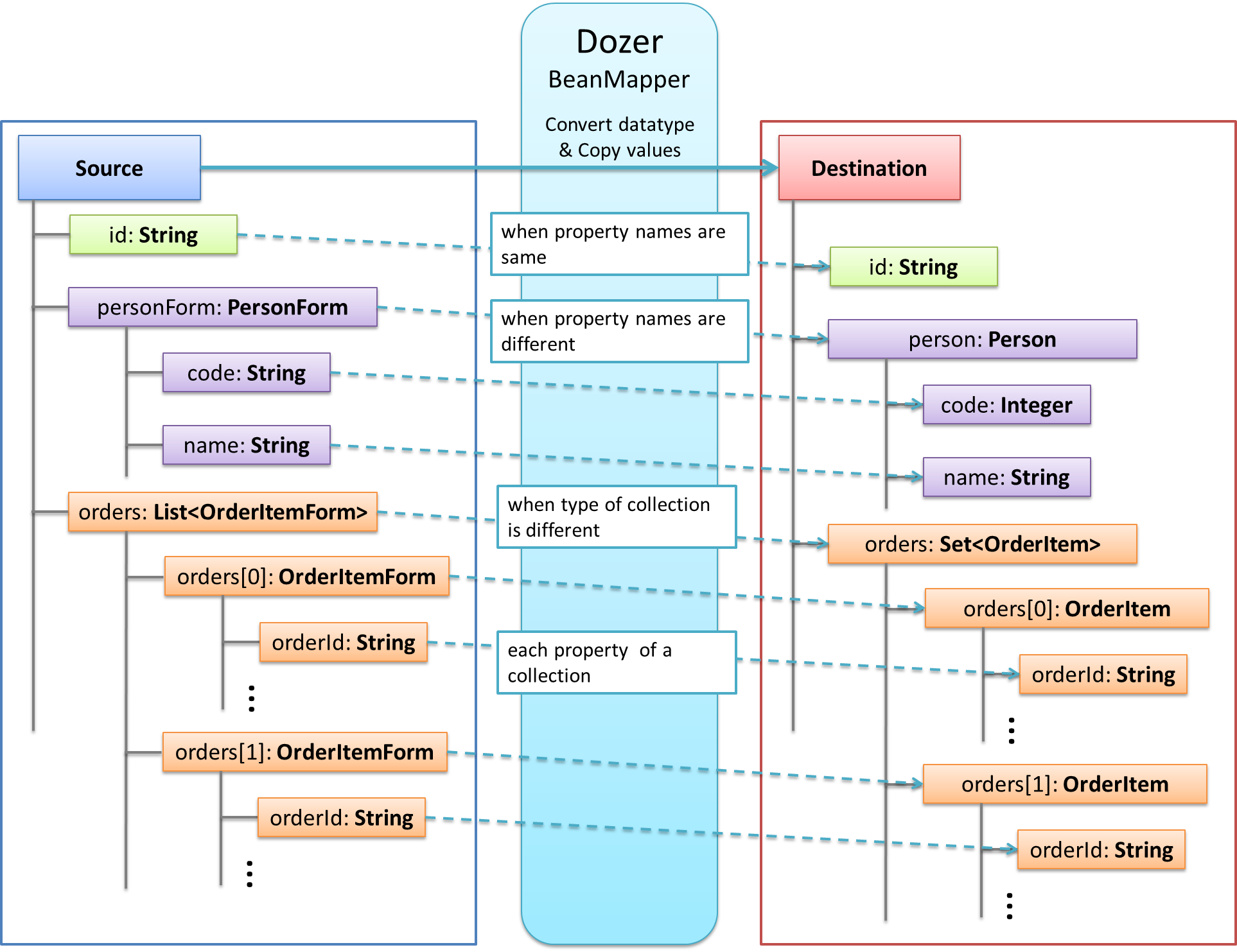
Dozerをした場合と使用しない場合のコード例を挙げる。
煩雑になり、プログラムの見通しが悪くなる例
User user = userService.findById(userId); XxxOutput output = new XxxOutput(); output.setUserId(user.getUserId()); output.setFirstName(user.getFirstName()); output.setLastName(user.getLastName()); output.setTitle(user.getTitle()); output.setBirthDay(user.getBirthDay()); output.setGender(user.getGender()); output.setStatus(user.getStatus());
Dozerを使用した場合の例
User user = userService.findById(userId); XxxOutput output = beanMapper.map(user, XxxOutput.class);
以降は、Dozerの利用方法について説明する。
Note
Dozer 6.4.0より、JSR-310 Date and Time APIが提供する以下のクラスのマッピングがサポートされた。
対象クラス :
java.time.LocalDatejava.time.LocalTimejava.time.LocalDateTimejava.time.OffsetTimejava.time.OffsetDateTimejava.time.ZonedDateTimeNote
Java SE 11環境にてDozerを利用する場合
Dozer 6.3.0より、マッピング定義XMLファイルの解析にデフォルトでJAXBが利用されるようになった。 Dozer 6.5.0より、Mavenを利用してJava SE 9以降でビルドするとjaxb-runtimeへの依存が推移的に解決されるため、JAXBを利用するために特別な設定を施す必要はない。
7.7.2. How to use¶
Dozerは、Java Beanのマッピング機能ライブラリである。 変換元のBeanから変換先のBeanに、再帰的(ネストした構造)に、値をコピーする。
7.7.2.1. Dozerを使用するためのBean定義¶
Dozerは、単独で使用するとき、以下のように、com.github.dozermapper.core.DozerBeanMapperBuilderを利用してMapper のインスタンスを作成する。
Mapper mapper = DozerBeanMapperBuilder.buildDefault();
Mapper のインスタンスを毎回作成するのは、効率が悪いため、
Dozerが提供しているcom.github.dozermapper.spring.DozerBeanMapperFactoryBeanを使用すること。
Bean定義ファイル(applicationContext.xml)に、Mapperを作成するFactoryクラスであるcom.github.dozermapper.spring.DozerBeanMapperFactoryBeanを定義する
<bean class="com.github.dozermapper.spring.DozerBeanMapperFactoryBean">
<property name="mappingFiles"
value="classpath*:/META-INF/dozer/**/*-mapping.xml" /><!-- (1) -->
</bean>
| 項番 | 説明 |
|---|---|
(1)
|
mappingFilesに、マッピング定義XMLファイルを指定する。
com.github.dozermapper.spring.DozerBeanMapperFactoryBeanは、 interfaceとして com.github.dozermapper.core.Mapperを保持している。そのため、 @Inject時は Mapperを指定する。この例では、クラスパス直下の、/META-INF/dozerの任意フォルダ内の
(任意の値)-mapping.xmlを、すべて読み込む。このXMLファイルの内容については、以降で説明する。
|
Beanマッピングを行いたいクラスに、Mapperをインジェクトすればよい。
@Inject
Mapper beanMapper;
7.7.2.2. Bean間のフィールド名、型が同じ場合のマッピング¶
デフォルトの動作として、Dozerは対象のBean間のフィールド名が同じであれば、マッピング定義XMLファイルを作成せずにマッピングできる。
変換元のBean定義
public class Source {
private int id;
private String name;
// omitted setter/getter
}
変換先のBean定義
public class Destination {
private int id;
private String name;
// omitted setter/getter
}
以下のように、Mapperの mapメソッドを使ってBeanマッピングを行う。
下記メソッドを実行した後、Destinationオブジェクトが新たに作成され、sourceの各フィールドの値が作成されたDestinationオブジェクトにコピーされる。
Source source = new Source();
source.setId(1);
source.setName("SourceName");
Destination destination = beanMapper.map(source, Destination.class); // (1)
System.out.println(destination.getId());
System.out.println(destination.getName());
| 項番 | 説明 |
|---|---|
(1)
|
第一引数に、コピー元のオブジェクトを渡し、第二引数に、コピー先のBeanのクラスを渡す。
|
上記のコードを実行すると以下のように出力される。作成されたオブジェクトにコピー元のオブジェクトの値が設定されていることが分かる。
1
SourceName
既に存在しているdestinationオブジェクトに、sourceオブジェクトのフィールドをコピーしたい場合は、
Source source = new Source();
source.setId(1);
source.setName("SourceName");
Destination destination = new Destination();
destination.setId(2);
destination.setName("DestinationName");
beanMapper.map(source, destination); // (1)
System.out.println(destination.getId());
System.out.println(destination.getName());
| 項番 | 説明 |
|---|---|
(1)
|
第一引数に、コピー元のオブジェクトを渡し、第二引数に、コピー先のオブジェクトを渡す。
|
上記のコードを実行すると以下のように出力される。コピー元のオブジェクトの値がコピー先に反映されていることが分かる。
1
SourceName
Note
DestinationクラスのフィールドでSourceクラスに存在しないものは、コピー前後で値は変わらない。
変換元のBean定義
public class Source { private int id; private String name; // omitted setter/getter }
変換先のBean定義
public class Destination { private int id; private String name; private String title; // omitted setter/getter }
マッピング例
Source source = new Source(); source.setId(1); source.setName("SourceName"); Destination destination = new Destination(); destination.setId(2); destination.setName("DestinationName"); destination.setTitle("DestinationTitle"); beanMapper.map(source, destination); System.out.println(destination.getId()); System.out.println(destination.getName()); System.out.println(destination.getTitle());
上記のコードを実行すると以下のように出力される。Sourceクラスにはtitleフィールドが
ないため、Destinationオブジェクトのtitleフィールドは、コピー前のフィールド値から変更がない。
1 SourceName DestinationTitle
7.7.2.3. Bean間のフィールド名は同じ、型が異なる場合のマッピング¶
コピー元と、コピー先でBeanのフィールドの型が異なる場合、 型変換がサポートされている型は、自動でマッピングできる。
以下のような変換は、マッピング定義XMLファイル無しで変換できる。
例 : String -> BigDecimal
変換元のBean定義
public class Source {
private String amount;
// omitted setter/getter
}
変換先のBean定義
public class Destination {
private BigDecimal amount;
// omitted setter/getter
}
マッピング例
Source source = new Source();
source.setAmount("123.45");
Destination destination = beanMapper.map(source, Destination.class);
System.out.println(destination.getAmount());
上記のコードを実行すると以下のように出力される。型が異なる場合でも値をコピーできていることが分かる。
123.45
サポートされている型変換については、 マニュアル を参照されたい。
7.7.2.4. Bean間のフィールド名が異なる場合のマッピング¶
コピー元と、コピー先でフィールド名が異なる場合、マッピング定義XMLファイルを作成し、 Beanマッピングするフィールドを定義することで変換できる。
変換元のBean定義
public class Source {
private int id;
private String name;
// omitted setter/getter
}
変換先のBean定義
public class Destination {
private int destinationId;
private String destinationName;
// omitted setter/getter
}
Dozerを使用するためのBean定義の定義がある場合、 src/main/resources/META-INF/dozerフォルダ内に、(任意の値)-mapping.xmlという、マッピング定義XMLファイルを作成する。
<?xml version="1.0" encoding="UTF-8"?>
<mappings xmlns="http://dozermapper.github.io/schema/bean-mapping" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://dozermapper.github.io/schema/bean-mapping
https://dozermapper.github.io/schema/bean-mapping.xsd">
<mapping>
<class-a>com.xx.xx.Source</class-a><!-- (1) -->
<class-b>com.xx.xx.Destination</class-b><!-- (2) -->
<field>
<a>id</a><!-- (3) -->
<b>destinationId</b><!-- (4) -->
</field>
<field>
<a>name</a>
<b>destinationName</b>
</field>
</mapping>
</mappings>
| 項番 | 説明 |
|---|---|
(1)
|
<class-a>タグ内にコピー元のBeanの、完全修飾クラス名(FQCN)を指定する。 |
(2)
|
<class-b>タグ内にコピー先のBeanの、完全修飾クラス名(FQCN)を指定する。 |
(3)
|
<field>タグ内の<a>タグ内にコピー元のBeanの、マッピング用のフィールド名を指定する。 |
(4)
|
<field>タグ内の<b>タグ内に(3)に対応するコピー先のBeanの、マッピング用のフィールド名を指定する。 |
マッピング例
Source source = new Source();
source.setId(1);
source.setName("SourceName");
Destination destination = beanMapper.map(source, Destination.class); // (1)
System.out.println(destination.getDestinationId());
System.out.println(destination.getDestinationName());
| 項番 | 説明 |
|---|---|
(1)
|
第一引数に、コピー元のオブジェクトを渡し、第二引数に、コピー先のBeanのクラスを渡す。(基本マッピングと違いはない。)
|
上記のコードを実行すると以下のように出力される。
1
SourceName
Dozerを使用するためのBean定義の設定によって、mappingFilesプロパティにクラスパス直下のMETA-INF/dozer配下に存在するマッピング定義XMLファイルが読み込まれる。
ファイル名は(任意の値)-mapping.xmlである必要がある。
いずれかのファイル内にSourceクラスとDestinationクラス間におけるマッピング定義があれば、その設定が適用される。
Note
マッピング定義XMLファイルは、Controller単位で作成し、ファイル名は、(Controller名からControllerを除いた値)-mapping.xmlにすることを推奨する。 例えば、TodoControllerに対するマッピング定義XMLファイルは、src/main/resources/META-INF/dozer/todo-mapping.xmlに作成する。
Note
本ガイドラインでは解説しないが、マッピング定義XMLファイルにおいてEL式を使用することができる。
EL式の解釈にはJakarta EE(Java EE)の標準APIを用いており、デフォルトではcom.sun.el.ExpressionFactoryImplクラスが利用される。
利用する実装クラスはjavax.el.ExpressionFactoryシステムプロパティにより切り替えることが可能である。
なお、ブランクプロジェクトのデフォルト設定では依存関係に標準APIの実装ライブラリが存在しないため 実行環境によっては起動時ログに以下のような警告が表示されるが、EL式を利用しない場合は実行に支障はないため無視して良い。
X-Track: level:WARN logger:c.github.dozermapper.core.el.ELExpressionFactory message:javax.el is not supported; Failed to resolve ExpressionFactory, com.sun.el.ExpressionFactoryImpl
詳細は、Expression Language を参照されたい。
7.7.2.5. 単方向・双方向マッピング¶
マッピングXMLで定義されているマッピングは、デフォルトで、双方向マッピングである。
すなわち前述の例ではSourceオブジェクトからDestinationオブジェクトへのマッピングを行ったが、
DestinationオブジェクトからSourceオブジェクトのマッピングも可能である。
単方向のみを指定したい場合は、マッピング・フィールド定義に、<mapping>タグのtype属性にone-wayを設定する。
<?xml version="1.0" encoding="UTF-8"?>
<mappings xmlns="http://dozermapper.github.io/schema/bean-mapping" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://dozermapper.github.io/schema/bean-mapping
https://dozermapper.github.io/schema/bean-mapping.xsd">
<!-- omitted -->
<mapping type="one-way">
<class-a>com.xx.xx.Source</class-a>
<class-b>com.xx.xx.Destination</class-b>
<field>
<a>id</a>
<b>destinationId</b>
</field>
<field>
<a>name</a>
<b>destinationName</b>
</field>
</mapping>
<!-- omitted -->
</mappings>
変換元のBean定義
public class Source {
private int id;
private String name;
// omitted setter/getter
}
変換先のBean定義
public class Destination {
private int destinationId;
private String destinationName;
// omitted setter/getter
}
マッピング例
Source source = new Source();
source.setId(1);
source.setName("SourceName");
Destination destination = beanMapper.map(source, Destination.class);
System.out.println(destination.getDestinationId());
System.out.println(destination.getDestinationName());
上記のコードを実行すると以下のように出力される。
1
SourceName
単方向を指定している場合に、逆方向のマッピングを行ってもエラーは発生しない。コピー処理は無視される。
なぜなら、マッピング定義がないとDestinationのフィールドに該当するSourceのフィールドが存在ないとみなされるためである。
Destination destination = new Destination();
destination.setDestinationId(2);
destination.setDestinationName("DestinationName");
Source source = new Source();
source.setId(1);
source.setName("SourceName");
beanMapper.map(destination, source);
System.out.println(source.getId());
System.out.println(source.getName());
上記のコードを実行すると以下のように出力される。
1
SourceName
Note
Dozer 6.1.0以前のバージョンに存在する単方向マッピングのバグについて
Dozer 6.1.0以前では、同名フィールドは<mapping>タグのtype属性にone-wayを付与しても正常に単方向マッピングとならず、逆方向でもマッピングされるバグが存在する。
Macchinetta Server Framework 1.5.X以前はDozer 6.1.0以前のバージョンを使用しているため、バグの影響を受けていた。
具体的には、<mapping>タグのtype属性にone-wayを付与した場合、フィールドが別名であれば正常に単方向マッピングとなる。
それ以外の項目は双方向マッピングされてしまう。
具体例を以下に示す。
変換元のBean定義
public class Source { private int id; private String sameNameField1; private String sameNameField2; // omitted setter/getter }
変換先のBean定義
public class Destination { private int destinationId; private String sameNameField1; private String sameNameField2; // omitted setter/getter }
マッピング定義
<mapping type="one-way"> <class-a>xxx.Source</class-a> <class-b>xxx.Destination</class-b> <!-- fieldタグを利用してマッピング定義した異名フィールドは、正常に単方向マッピングとなる。 --> <field> <a>id</a> <b>destinationId</b> </field> <!-- fieldタグを利用してマッピング定義した同名フィールドは、双方向マッピングとなってしまう。 --> <field> <a>sameNameField1</a> <b>sameNameField1</b> </field> <!-- 自動でマッピングされた同名フィールド(sameNameField2)も、双方向マッピングとなってしまう。 --> </mapping>
上記のようにマッピング定義した場合、sameNameField1、sameNameField2は逆方向にもマッピングされてしまっていた。
7.7.2.6. Nestしたフィールドのマッピング¶
コピー元Beanが持つフィールドを、コピー先Beanが持つNestしたBeanのフィールドにも、マッピングできることである。 (Dozerの用語で、 Deep Mapping と呼ばれる。)
変換元のBean定義
public class EmployeeForm {
private int id;
private String name;
private String deptId;
// omitted setter/getter
}
変換先のBean定義
public class Employee {
private Integer id;
private String name;
private Department department;
// omitted setter/getter
}
public class Department {
private String deptId;
// omitted setter/getter and other fields
}
例 : EmployeeFormオブジェクトが持つdeptIdを、Employeeオブジェクトが持つDepartmentのdeptIdにマップしたい場合、
以下のように定義する。
<?xml version="1.0" encoding="UTF-8"?>
<mappings xmlns="http://dozermapper.github.io/schema/bean-mapping" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://dozermapper.github.io/schema/bean-mapping
https://dozermapper.github.io/schema/bean-mapping.xsd">
<!-- omitted -->
<mapping map-empty-string="false" map-null="false">
<class-a>com.xx.aa.EmployeeForm</class-a>
<class-b>com.xx.bb.Employee</class-b>
<field>
<a>deptId</a>
<b>department.deptId</b><!-- (1) -->
</field>
</mapping>
<!-- omitted -->
</mappings>
| 項番 | 説明 |
|---|---|
(1)
|
EmployeeフォームのdeptIdに対する、Employeeオブジェクトのフィールドを指定する。 |
マッピング例
EmployeeForm source = new EmployeeForm();
source.setId(1);
source.setName("John");
source.setDeptId("D01");
Employee destination = beanMapper.map(source, Employee.class);
System.out.println(destination.getId());
System.out.println(destination.getName());
System.out.println(destination.getDepartment().getDeptId());
上記のコードを実行すると以下のように出力される。
1
John
D01
上記の場合は、変換先クラスであるEmployeeの新規インスタンスが作成される。
Employeeの中のdepartment フィールドにも、新規に作成されたDepartmentインスタンスが設定され、
EmployeeFormのdeptIdが、コピーされる。
下記のようにEmployeeの中のdepartment フィールドに既にDepartmentオブジェクトが設定されている場合は、
新規インスタンスは作成されず、既存のDepartmentオブジェクトのdeptIdフィールドに、
EmployeeFormのdeptIdがコピーされる。
EmployeeForm source = new EmployeeForm();
source.setId(1);
source.setName("John");
source.setDeptId("D01");
Employee destination = new Employee();
Department department = new Department();
destination.setDepartment(department);
beanMapper.map(source, destination);
System.out.println(department.getDeptId());
System.out.println(destination.getDepartment() == department);
上記のコードを実行すると以下のように出力される。
D01
true
7.7.2.7. Collectionマッピング¶
Dozerは、以下のCollectionタイプの双方向自動マッピングをサポートしている。 フィールド名が同じである場合、マッピング定義XMLファイルが不要である。
java.util.List<=>java.util.Listjava.util.List<=> Array- Array <=> Array
java.util.Set<=>java.util.Setjava.util.Set<=> Arrayjava.util.Set<=>java.util.List
次のクラスのコレクションをもつBeanのマッピングについて考える。
package com.example.dozer;
public class Email {
private String email;
public Email() {
}
public Email(String email) {
this.email = email;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
@Override
public String toString() {
return email;
}
// generated by Eclipse
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + ((email == null) ? 0 : email.hashCode());
return result;
}
// generated by Eclipse
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Email other = (Email) obj;
if (email == null) {
if (other.email != null)
return false;
} else if (!email.equals(other.email))
return false;
return true;
}
}
変換元のBean
package com.example.dozer;
import java.util.List;
public class AccountForm {
private List<Email> emails;
public void setEmails(List<Email> emails) {
this.emails = emails;
}
public List<Email> getEmails() {
return emails;
}
}
変換先のBean
package com.example.dozer;
import java.util.List;
public class Account {
private List<Email> emails;
public void setEmails(List<Email> emails) {
this.emails = emails;
}
public List<Email> getEmails() {
return emails;
}
}
マッピング例
AccountForm accountForm = new AccountForm();
List<Email> emailsSrc = new ArrayList<Email>();
emailsSrc.add(new Email("a@example.com"));
emailsSrc.add(new Email("b@example.com"));
emailsSrc.add(new Email("c@example.com"));
accountForm.setEmails(emailsSrc);
Account account = beanMapper.map(accountForm, Account.class);
System.out.println(account.getEmails());
上記のコードを実行すると以下のように出力される。
[a@example.com, b@example.com, c@example.com]
ここまではこれまで説明したことと特に変わりはない。
次の例のように、コピー先のBeanのCollectionフィールドに既に要素が追加されている場合は要注意である。
AccountForm accountForm = new AccountForm();
Account account = new Account();
List<Email> emailsSrc = new ArrayList<Email>();
List<Email> emailsDest = new ArrayList<Email>();
emailsSrc.add(new Email("a@example.com"));
emailsSrc.add(new Email("b@example.com"));
emailsSrc.add(new Email("c@example.com"));
emailsDest.add(new Email("a@example.com"));
emailsDest.add(new Email("d@example.com"));
emailsDest.add(new Email("e@example.com"));
accountForm.setEmails(emailsSrc);
account.setEmails(emailsDest);
beanMapper.map(accountForm, account);
System.out.println(account.getEmails());
上記のコードを実行すると以下のように出力される。
[a@example.com, d@example.com, e@example.com, a@example.com, b@example.com, c@example.com]
コピー元BeanのCollectionの全要素が、コピー先BeanのCollectionに追加されている。
a@exmample.comをもつ2つのEmailオブジェクトは”等価”であるが、単純に追加される。
(ここでいう”等価”とはEmail.equals で比較するとtrueになり、Email.hashCodeの値も同じであることを意味する。)
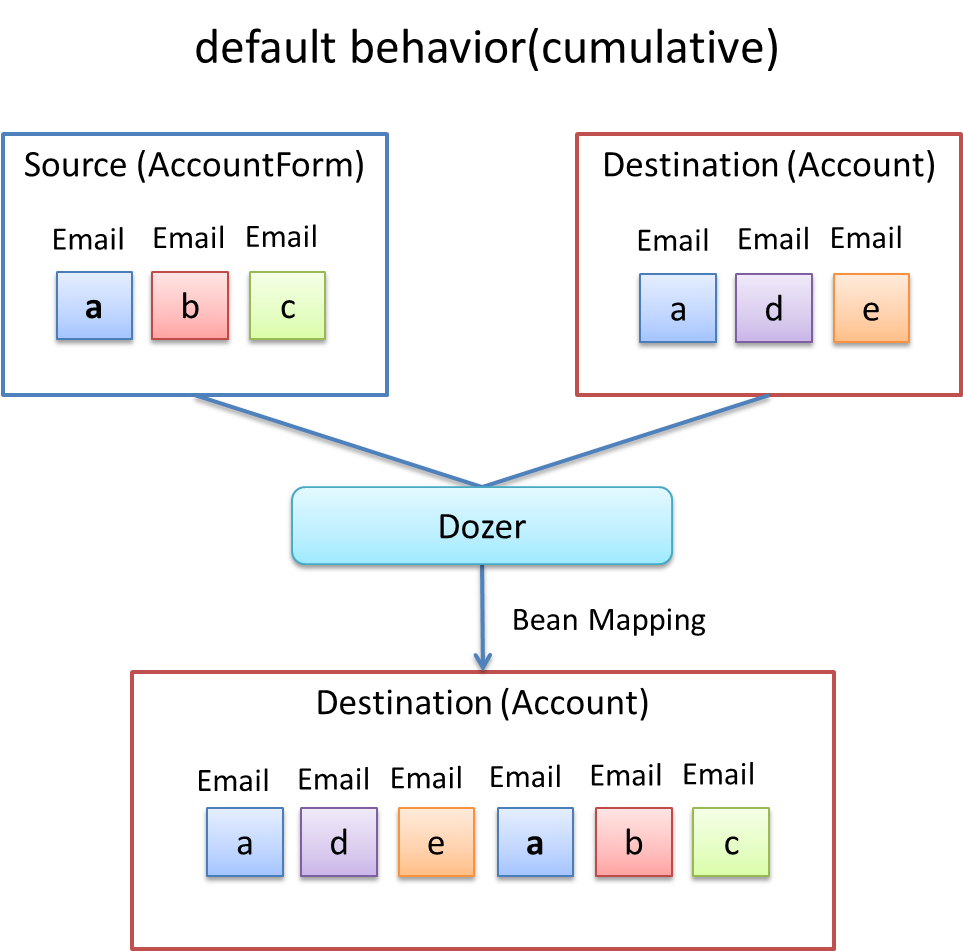
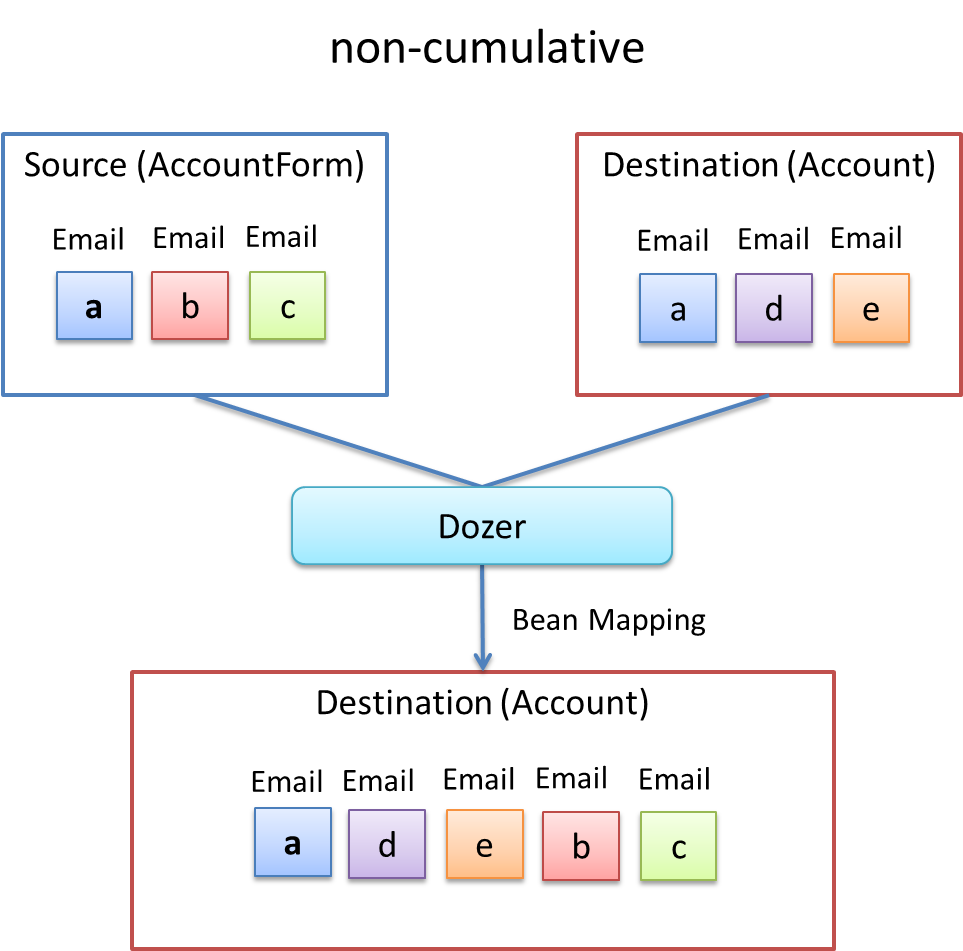
上記の振る舞いは、Dozerの用語ではcumulativeと呼ばれ、Collectionをマッピングする際のデフォルトの挙動となっている。
この挙動はマッピング定義XMLファイルにおいて変更することができる。
<?xml version="1.0" encoding="UTF-8"?>
<mappings xmlns="http://dozermapper.github.io/schema/bean-mapping" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://dozermapper.github.io/schema/bean-mapping
https://dozermapper.github.io/schema/bean-mapping.xsd">
<!-- omitted -->
<mapping>
<class-a>com.example.dozer.AccountForm</class-a>
<class-b>com.example.dozer.Account</class-b>
<field relationship-type="non-cumulative"><!-- (1) -->
<a>emails</a>
<b>emails</b>
</field>
</mapping>
<!-- omitted -->
</mappings>
| 項番 | 説明 |
|---|---|
(1)
|
<field>タグのrelationship-type属性にnon-cumulativeを指定する。デフォルト値はcumulativeである。マッピング対象のBeanの全フィールドに対して
non-cumulativeを指定したい場合は、<mapping>タグのrelationship-type属性にnon-cumulativeを指定することもできる。 |
この設定のもと、前述のコードを実行すると以下のように出力される。
[a@example.com, d@example.com, e@example.com, b@example.com, c@example.com]
等価であるオブジェクトの重複がなくなっていることが分かる。
Note
変換元のオブジェクトが、変換先のオブジェクトで更新されることに注意されたい。
上記の例ではAccountFormの中のa@exmample.comがコピー先に格納される。
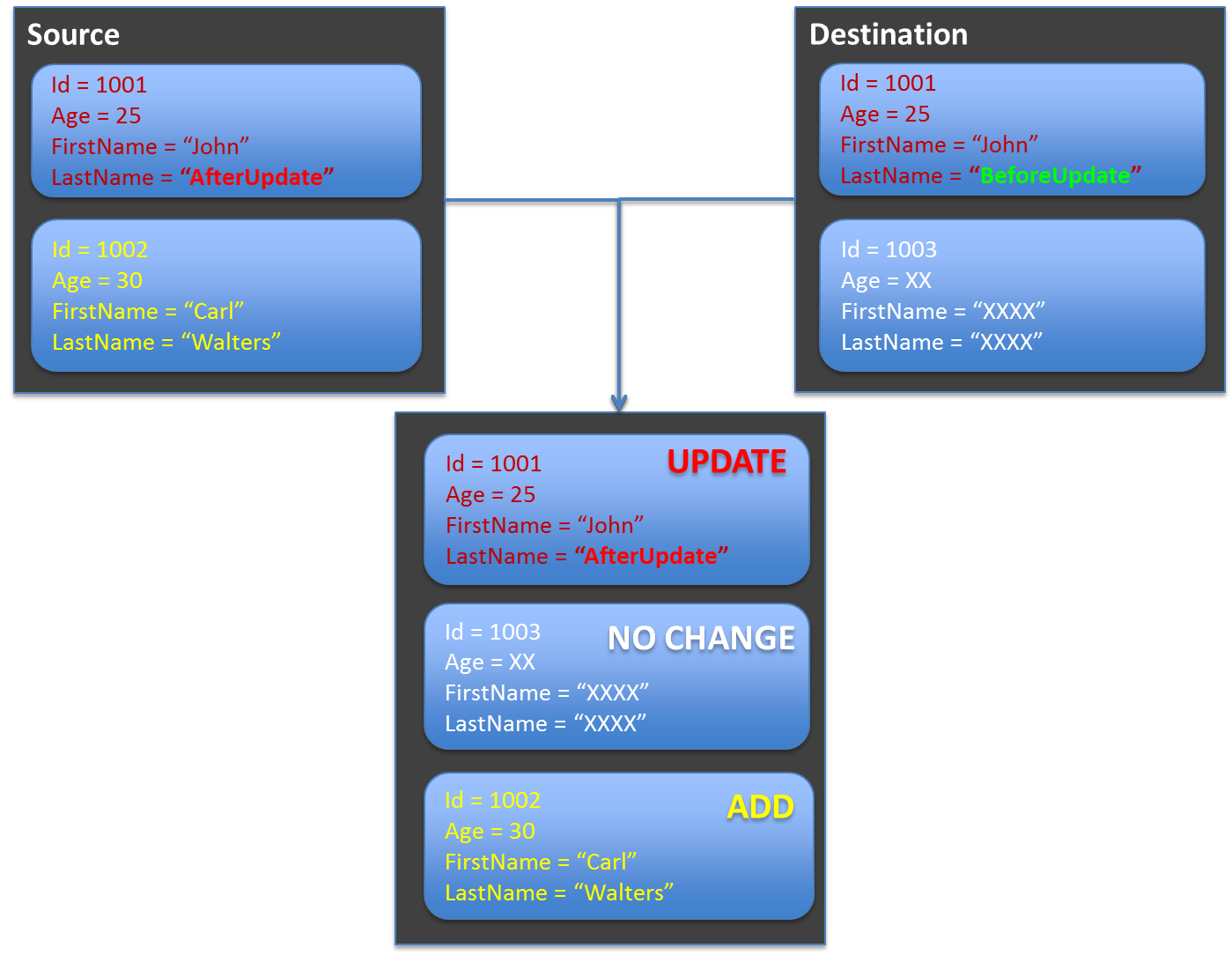
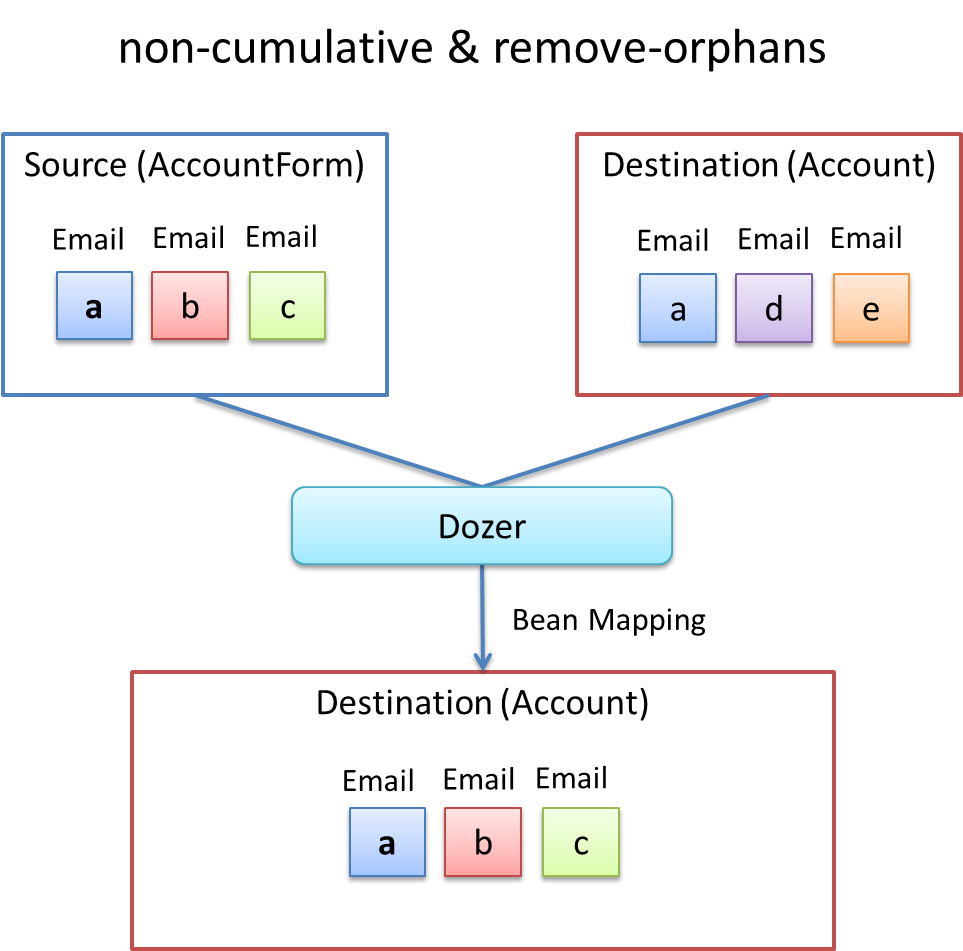
コピー先のコレクションにのみに存在する項目は除外したい場合も、マッピング定義XMLファイルの設定で実現することができる。
<?xml version="1.0" encoding="UTF-8"?>
<mappings xmlns="http://dozermapper.github.io/schema/bean-mapping" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://dozermapper.github.io/schema/bean-mapping
https://dozermapper.github.io/schema/bean-mapping.xsd">
<!-- omitted -->
<mapping>
<class-a>com.example.dozer.AccountForm</class-a>
<class-b>com.example.dozer.Account</class-b>
<field relationship-type="non-cumulative" remove-orphans="true" ><!-- (1) -->
<a>emails</a>
<b>emails</b>
</field>
</mapping>
<!-- omitted -->
</mappings>
| 項番 | 説明 |
|---|---|
(1)
|
<field>タグのremove-orphans属性にtrueを設定する。デフォルト値はfalseである。 |
この設定のもと、前述のコードを実行すると以下のように出力される。
[a@example.com, b@example.com, c@example.com]
コピー元にあるオブジェクトだけがコピー先のコレクション内に残っていることが分かる。
いかのように設定しても同じ結果が得られる。
<?xml version="1.0" encoding="UTF-8"?>
<mappings xmlns="http://dozermapper.github.io/schema/bean-mapping" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://dozermapper.github.io/schema/bean-mapping
https://dozermapper.github.io/schema/bean-mapping.xsd">
<!-- omitted -->
<mapping>
<class-a>com.example.dozer.AccountForm</class-a>
<class-b>com.example.dozer.Account</class-b>
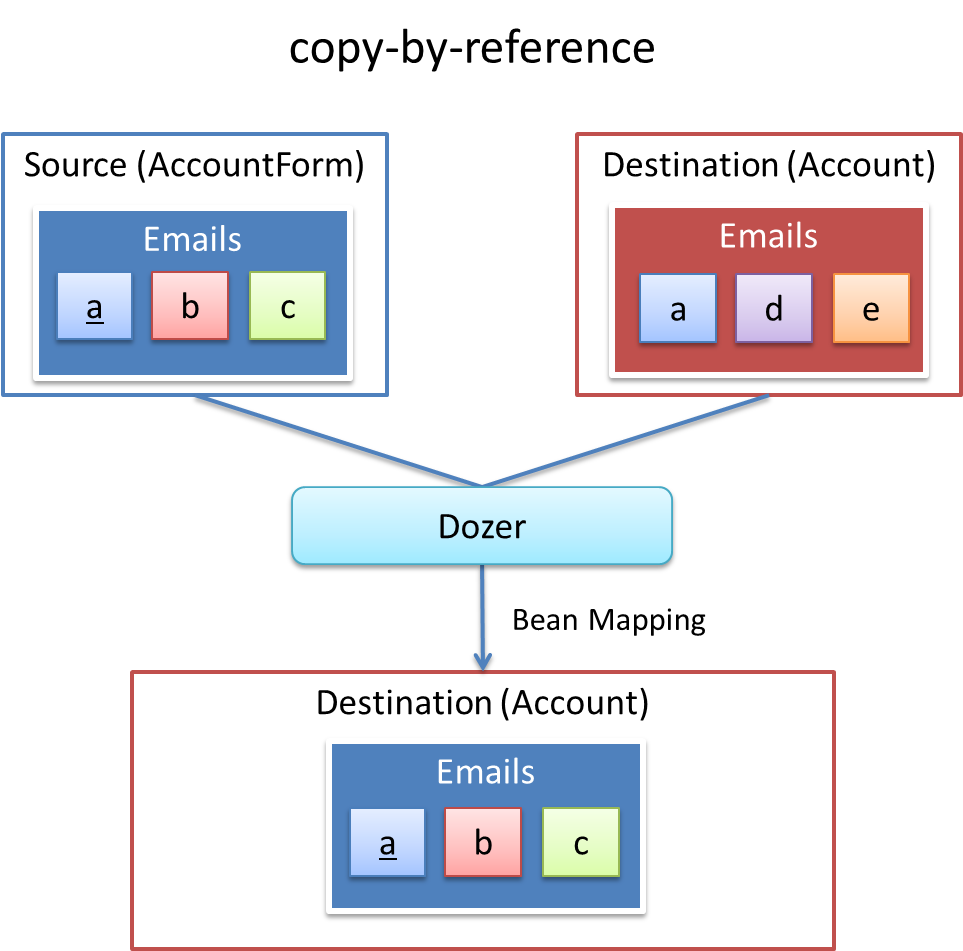
<field copy-by-reference="true"><!-- (1) -->
<a>emails</a>
<b>emails</b>
</field>
</mapping>
<!-- omitted -->
</mappings>
| 項番 | 説明 |
|---|---|
(1)
|
<field>タグのcopy-by-reference属性にtrueを設定する。デフォルト値はfalseである。 |
これまでの挙動を図で表現する。
デフォルトの挙動(cumulative)
non-cumulative
non-cumulativeかつremove-orphans=true
copy-by-referenceもこのパターンである。
Note
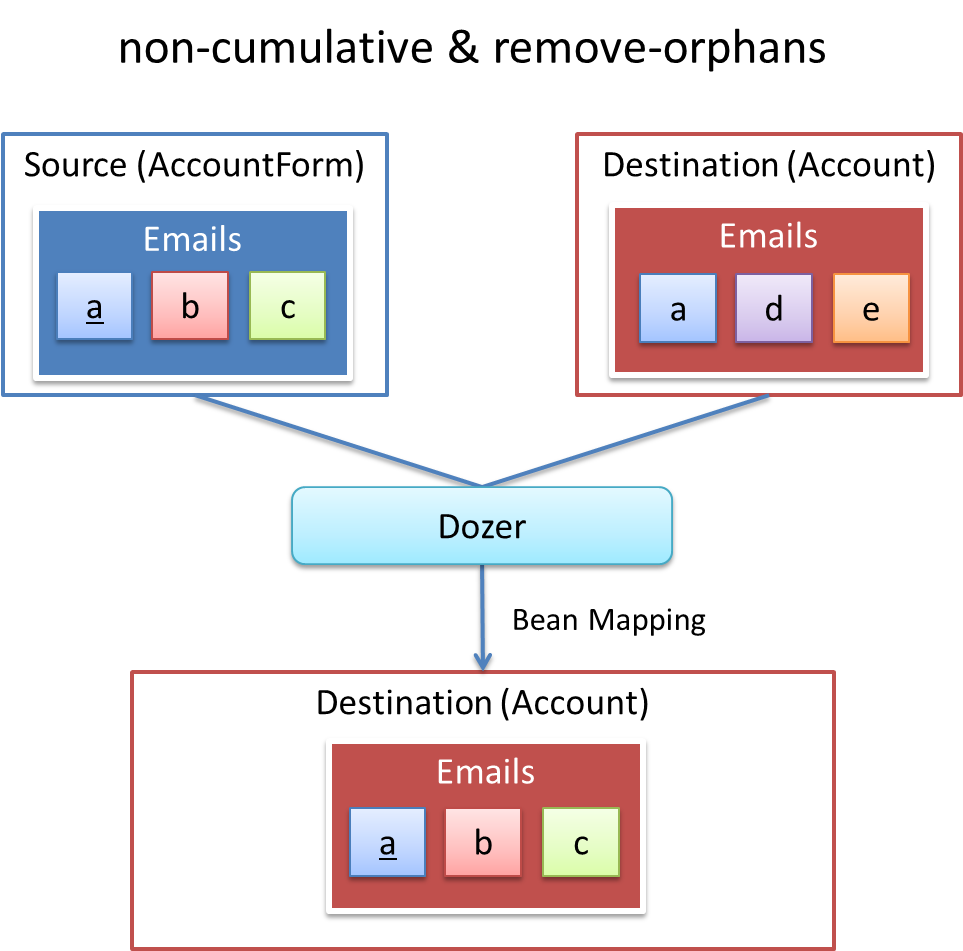
「non-cumulativeかつremove-orphans=true」のパターンと「copy-by-reference」のパターンの違いは、Bean変換後のCollectionのコンテナがコピー先のものか、コピー元のものかで異なる点である。
「non-cumulativeかつremove-orphans=true」のパターンの場合は、Bean変換後のCollectionのコンテナはコピー先のものであり、「copy-by-reference」のパターンはコピー元のものである。 以下に図で説明する。
non-cumulativeかつremove-orphans=true
copy-by-reference
Warning
マッピング対象のBeanがStringのコレクションを持つ場合、期待通りの挙動にならないバグがある。
StringListSrc src = new StringListSrc; StringListDest dest = new StringListDest(); List<String> stringsSrc = new ArrayList<String>(); List<String> stringsDest = new ArrayList<String>(); stringsSrc.add("a"); stringsSrc.add("b"); stringsSrc.add("c"); stringsDest.add("a"); stringsDest.add("d"); stringsDest.add("e"); src.setStrings(stringsSrc); dest.setStrings(stringsDest); beanMapper.map(src, dest); System.out.println(dest.getStrings());
上記のコードをnon-cumulativeかつremove-orphans=trueの設定で実行すると、
[a, b, c]
と出力されることを期待するが、実際には
[b, c]
と出力され、重複したStringが除かれてしまう。
copy-by-reference=”true”の設定で実行すると、期待通り
[a, b, c]
と出力される。
Tip
Dozerでは、Genericsを使用しないリスト間でもマッピングできる。このとき、変換元と変換先に含まれているオブジェクトのデータ型をHINTとして指定できる。 詳細は、 Dozerの公式マニュアル -Collection and Array Mapping(Using Hints for Collection Mapping)- を参照されたい。
7.7.3. How to extend¶
7.7.3.1. カスタムコンバーターの作成¶
- 例 :
java.lang.String<=>org.joda.time.DateTime
com.github.dozermapper.core.CustomConverterを実装したクラスである。- Global Configuration
- クラスレベル
- フィールドレベル
アプリケーション全体で、同様のロジックにより変換を行いたい場合は、Global Configurationを推奨する。
カスタムコンバーターを実装する場合はcom.github.dozermapper.core.DozerConverterを継承するのが便利である。
package com.example.yourproject.common.bean.converter;
import com.github.dozermapper.core.DozerConverter;
import org.joda.time.DateTime;
import org.joda.time.format.DateTimeFormat;
import org.joda.time.format.DateTimeFormatter;
import org.springframework.util.StringUtils;
public class StringToJodaDateTimeConverter extends
DozerConverter<String, DateTime> { // (1)
public StringToJodaDateTimeConverter() {
super(String.class, DateTime.class); // (2)
}
@Override
public DateTime convertTo(String source, DateTime destination) {// (3)
if (!StringUtils.hasLength(source)) {
return null;
}
DateTimeFormatter formatter = DateTimeFormat
.forPattern("yyyy-MM-dd HH:mm:ss");
DateTime dt = formatter.parseDateTime(source);
return dt;
}
@Override
public String convertFrom(DateTime source, String destination) {// (4)
if (source == null) {
return null;
}
return source.toString("yyyy-MM-dd HH:mm:ss");
}
}
| 項番 | 説明 |
|---|---|
(1)
|
com.github.dozermapper.core.DozerConverterを継承する。 |
(2)
|
コンストラクタで対象の2つのクラスを設定する。
|
(3)
|
StringからDateTimeの変換ロジックを記述する。本例ではデフォルトLocaleを使用する。 |
(4)
|
DateTimeからStringの変換ロジックを記述する。本例ではデフォルトLocaleを使用する。 |
作成したカスタムコンバーターを、マッピングに利用するために定義する必要がある。
dozer-configration-mapping.xml
<?xml version="1.0" encoding="UTF-8"?>
<mappings xmlns="http://dozermapper.github.io/schema/bean-mapping" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://dozermapper.github.io/schema/bean-mapping
https://dozermapper.github.io/schema/bean-mapping.xsd">
<configuration>
<custom-converters><!-- (1) -->
<!-- these are always bi-directional -->
<converter
type="com.example.yourproject.common.bean.converter.StringToJodaDateTimeConverter"><!-- (2) -->
<class-a>java.lang.String</class-a><!-- (3) -->
<class-b>org.joda.time.DateTime</class-b><!-- (4) -->
</converter>
</custom-converters>
</configuration>
<!-- omitted -->
</mappings>
| 項番 | 説明 |
|---|---|
(1)
|
すべてのカスタムコンバーターが属する、
custom-convertersを定義する。 |
(2)
|
個別の変換の行うconverterを定義する。converterのタイプに、実装クラスの完全修飾クラス名(FQCN)を指定する。
|
(3)
|
変換元Beanの完全修飾クラス名(FQCN)
|
(4)
|
変換先Beanの完全修飾クラス名(FQCN)
|
上記のマッピングを行ったことで、アプリケーション全体で、java.lang.String<=> org.joda.time.DateTimeの変換が必要な場合、標準のマッピングではなく、カスタムコンバーター呼び出しでマッピングが行われる。
例 :
変換元のBean定義
public class Source {
private int id;
private String date;
// omitted setter/getter
}
変換先のBean定義
public class Destination {
private int id;
private DateTime date;
// omitted setter/getter
}
マッピング (双方向例)
Source source = new Source();
source.setId(1);
source.setDate("2012-08-10 23:12:12");
DateTimeFormatter formatter = DateTimeFormat.forPattern("yyyy-MM-dd HH:mm:ss");
DateTime dt = formatter.parseDateTime(source.getDate());
// Source to Destination Bean Mapping (String to org.joda.time.DateTime)
Destination destination = dozerBeanMapper.map(source, Destination.class);
assertThat(destination.getId(), is(1));
assertThat(destination.getDate(),is(dt));
// Destination to Source Bean Mapping (org.joda.time.DateTime to String)
dozerBeanMapper.map(destination, source);
assertThat(source.getId(), is(1));
assertThat(source.getDate(),is("2012-08-10 23:12:12"));
カスタムコンバーターに関する詳細は、 Dozerの公式マニュアル -Custom Converters- を参照されたい。
Note
Stringからjava.util.Dateなど標準の日付・時刻オブジェクトへの変換については”文字列から日付・時刻オブジェクトへのマッピング”で述べる。
7.7.4. Appendix¶
マッピング定義XMLファイルで指定できるオプションを説明する。
すべてのオプションは、 Dozerの公式マニュアル -Custom Mappings Via Dozer XML Files- で確認できる。
7.7.4.1. フィールド除外設定 (field-exclude)¶
Beanを変換する際に、コピーしてほしくないフィールドを除外することができる。
以下のようなBeanの変換を考える。
変換元のBean定義
public class Source {
private int id;
private String name;
private String title;
// omitted setter/getter
}
コピー先のBean定義
public class Destination {
private int id;
private String name;
private String title;
// omitted setter/getter
}
コピー元のBeanから任意のフィールドをマッピングから除外したい場合は以下のように定義する。
フィールド除外の設定は、マッピング定義XMLファイルで、以下のように行う。
<?xml version="1.0" encoding="UTF-8"?>
<mappings xmlns="http://dozermapper.github.io/schema/bean-mapping" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://dozermapper.github.io/schema/bean-mapping
https://dozermapper.github.io/schema/bean-mapping.xsd">
<!-- omitted -->
<mapping>
<class-a>com.xx.xx.Source</class-a>
<class-b>com.xx.xx.Destination</class-b>
<field-exclude><!-- (1) -->
<a>title</a>
<b>title</b>
</field-exclude>
</mapping>
<!-- omitted -->
</mappings>
| 項番 | 説明 |
|---|---|
(1)
|
除外したいフィールドを、<field-exclude>要素で設定する。この例の場合、指定した上でmapメソッドを実行すると、SourceオブジェクトからDestinationオブジェクトをコピーする際に、destinationのtitleの値が、上書きされない。
|
Source source = new Source();
source.setId(1);
source.setName("SourceName");
source.setTitle("SourceTitle");
Destination destination = new Destination();
destination.setId(2);
destination.setName("DestinationName");
destination.setTitle("DestinationTitle");
beanMapper.map(source, destination);
System.out.println(destination.getId());
System.out.println(destination.getName());
System.out.println(destination.getTitle());
上記のコードを実行すると以下のように出力される。
1
SourceName
DestinationTitle
マッピング後、destinationのtitleの値は、前の状態のままである。
7.7.4.2. マッピングの特定化 (map-id)¶
フィールド除外設定 (field-exclude)で示したマッピングは、アプリケーション全体でBean変換する際に適用される。 マッピングの適用範囲を制限(特定化)したい場合は、以下のように、map-idを指定して定義する。
<?xml version="1.0" encoding="UTF-8"?>
<mappings xmlns="http://dozermapper.github.io/schema/bean-mapping" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://dozermapper.github.io/schema/bean-mapping
https://dozermapper.github.io/schema/bean-mapping.xsd">
<!-- omitted -->
<mapping map-id="mapidTitleFieldExclude">
<class-a>com.xx.xx.Source</class-a>
<class-b>com.xx.xx.Destination</class-b>
<field-exclude>
<a>title</a>
<b>title</b>
</field-exclude>
</mapping>
<!-- omitted -->
</mappings>
上記の設定を行うと、mapメソッドにmap-id(mapidTitleFieldExclude)を渡すことでtitleのコピーを除外できる。
map-idを指定しない場合はこの設定は適用されず、全フィールドがコピーされる。
mapメソッドにmap-idを渡す例を、以下に示す。
Source source = new Source();
source.setId(1);
source.setName("SourceName");
source.setTitle("SourceTitle");
Destination destination1 = new Destination();
destination1.setId(2);
destination1.setName("DestinationName");
destination1.setTitle("DestinationTitle");
beanMapper.map(source, destination1); // (1)
System.out.println(destination1.getId());
System.out.println(destination1.getName());
System.out.println(destination1.getTitle());
Destination destination2 = new Destination();
destination2.setId(2);
destination2.setName("DestinationName");
destination2.setTitle("DestinationTitle");
beanMapper.map(source, destination2, "mapidTitleFieldExclude"); // (2)
System.out.println(destination2.getId());
System.out.println(destination2.getName());
System.out.println(destination2.getTitle());
| 項番 | 説明 |
|---|---|
(1)
|
通常のマッピング。
|
(2)
|
第三引数にmap-idを渡し、特定のマッピングルールを適用する。
|
上記のコードを実行すると以下のように出力される。
1
SourceName
SourceTitle
1
SourceName
DestinationTitle
Tip
map-idの指定は、mapping項目だけでなく、フィールドの定義でも行える。 詳細は、 Dozerの公式マニュアル -Context Based Mapping- を参照されたい。
Note
Webアプリケーションにおいて、新規追加・更新両方の操作で同じフォームオブジェクトを使う場合がある。
このとき、フォームオブジェクトをドメインオブジェクトにコピー(マップ)する上で、操作によってはコピーしたくないフィールドもある。
この場合に、<field-exclude>を使用する。
- 例:新規作成のフォームではuserIdを含むが、更新用のフォームではuserIdを含まない。
この場合に同じフォームオブジェクトを使用すると、更新時にuserIdにnullが設定される。コピー先のオブジェクトをDBから取得して、 フォームオブジェクトをそのままコピーすると、コピー先のuserIdまでnullとなる。これを回避するために、 更新用のmap-idを用意し、更新時はuserIdに対して、フィールド除外の設定を行う。
7.7.4.3. コピー元のnull・空フィールドを除外する設定 (map-null, map-empty)¶
コピー元のBeanのフィールドが、nullの場合、あるいは空の場合に、マッピングから除外することができる。
以下のように、マッピング定義XMLファイルに設定する。
<?xml version="1.0" encoding="UTF-8"?>
<mappings xmlns="http://dozermapper.github.io/schema/bean-mapping" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://dozermapper.github.io/schema/bean-mapping
https://dozermapper.github.io/schema/bean-mapping.xsd">
<!-- omitted -->
<mapping map-null="false" map-empty-string="false"><!-- (1) -->
<class-a>com.xx.xx.Source</class-a>
<class-b>com.xx.xx.Destination</class-b>
</mapping>
<!-- omitted -->
</mappings>
| 項番 | 説明 |
|---|---|
(1)
|
コピー元のBeanのフィールドが
nullの場合にマッピングから除外したい場合はmap-null属性にfalseを設定する。デフォルト値はtrueである。空の場合に、マッピングから除外したい場合は
map-empty-string属性にfalseを設定する。デフォルト値はtrueである。 |
変換元のBean定義
public class Source {
private int id;
private String name;
private String title;
// omitted setter/getter
}
変換先のBean定義
public class Destination {
private int id;
private String name;
private String title;
// omitted setter/getter
}
マッピング例
Source source = new Source();
source.setId(1);
source.setName(null);
source.setTitle("");
Destination destination = new Destination();
destination.setId(2);
destination.setName("DestinationName");
destination.setTitle("DestinationTitle");
beanMapper.map(source, destination);
System.out.println(destination.getId());
System.out.println(destination.getName());
System.out.println(destination.getTitle());
上記のコードを実行すると以下のように出力される。
1
DestinationName
DestinationTitle
コピー元Beanのnameとtitleフィールドは、null、あるいは空で、マッピングから除外されている。
7.7.4.4. 文字列から日付・時刻オブジェクトへのマッピング¶
コピー元の文字列型のフィールドを、コピー先の日付・時刻系のフィールドにマッピングできる。
以下の変換をサポートしている。
日付・時刻系
java.lang.String<=>java.util.Datejava.lang.String<=>java.util.Calendarjava.lang.String<=>java.util.GregorianCalendarjava.lang.String<=>java.sql.Timestampjava.lang.String<=>java.time.LocalDateTimejava.lang.String<=>java.time.OffsetDateTimejava.lang.String<=>java.time.ZonedDateTime
日付のみ
java.lang.String<=>java.sql.Datejava.lang.String<=>java.time.LocalDate
時刻のみ
java.lang.String<=>java.sql.Timejava.lang.String<=>java.time.LocalTimejava.lang.String<=>java.time.OffsetTime
java.time.LocalDateTimeへの変換を説明する。<?xml version="1.0" encoding="UTF-8"?>
<mappings xmlns="http://dozermapper.github.io/schema/bean-mapping" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://dozermapper.github.io/schema/bean-mapping
https://dozermapper.github.io/schema/bean-mapping.xsd">
<!-- omitted -->
<mapping>
<class-a>com.xx.xx.Source</class-a>
<class-b>com.xx.xx.Destination</class-b>
<field>
<a date-format="uuuu-MM-dd HH:mm:ss.SSS">date</a><!-- (1) -->
<b>date</b>
</field>
</mapping>
<!-- omitted -->
</mappings>
| 項番 | 説明 |
|---|---|
(1)
|
コピー元のフィールド名と日付形式を指定する。
|
変換元のBean定義
public class Source {
private String date;
// omitted setter/getter
}
変換先のBean定義
public class Destination {
private LocalDateTime date;
// omitted setter/getter
}
マッピング
Source source = new Source();
source.setDate("2013-10-10 11:11:11.111");
Destination destination = beanMapper.map(source, Destination.class);
assert(destination.getDate().equals(LocalDateTime.parse("2013-10-10 11:11:11.111", DateTimeFormatter.ofPattern("uuuu-MM-dd HH:mm:ss.SSS"))));
<?xml version="1.0" encoding="UTF-8"?>
<mappings xmlns="http://dozermapper.github.io/schema/bean-mapping" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://dozermapper.github.io/schema/bean-mapping
https://dozermapper.github.io/schema/bean-mapping.xsd">
<!-- omitted -->
<configuration>
<date-format>uuuu-MM-dd HH:mm:ss.SSS</date-format>
<!-- omitted other configuration -->
</configuration>
<!-- omitted -->
</mappings>
設定可能な項目の詳細について、 Dozerの公式マニュアル -Global Configuration- を参照されたい。
Warning
java.util.Dateとjava.time.LocalDateを併用するようなアプリケーションのとき、年形式にuuuuとyyyyを使い分ける必要があるため、アプリケーション全体で設定すると困るケースがある。このような場合では、アプリケーション全体の設定に加えて個別のマッピング定義で日付形式を設定すれば対応可能である。
Note
Java SE 11ではJava SE 8と日付の文字列表現が異なる場合がある。 Java SE 8と同様に表現するにはデフォルトで使用されるロケール・データの変更を参照されたい。
7.7.4.5. マッピングのエラー¶
マッピング中にマッピング処理が失敗したら、com.github.dozermapper.core.MappingException(実行時例外)がスローされる。
MappingException がスローされる代表的な例を、以下に挙げる。
mapメソッドに存在しないmap-idが渡されている。mapメソッドに存在するmap-idを渡したが、マップ処理に渡したソース・ターゲット型は、そのmap-idに指定している定義とは異なる。- Dozerがサポートしていない変換の場合、かつ、その変換用のカスタムコンバーターも存在しない場合。
これらは通常プログラムバグであるので、mapメソッドの呼び出しの部分を正しく修正する必要がある。
Warning
Dozer 6.3.0から、マッピング定義XMLファイルの解析にデフォルトでJAXBが利用されるようになった。 これにより、Dozer 6.2.0以前では無視されていたマッピング定義XMLファイルのコンテンツ部の両端に存在する改行コードは、Dozer 6.3.0以降では値として読み取られるようになった。
マッピング定義XMLファイルのコンテンツ部の両端に改行コードが存在する場合、指定されたフィールド名が正しく認識されない等の不具合が生じる可能性があるため、注意されたい。