3.6. データ永続層のスケール性の確保¶
目次
3.6.1. Overview¶
データベースにRDBを使う場合は、RDBがスケール性を阻害する要素となる可能性がある。
本ガイドラインではその阻害を軽減する手法である、データのキャッシュ方式、シャーディング方式、リードレプリカ方式の概念について説明する。 キャッシュ方式とシャーディング方式の実装編については、データアクセス を参照されたい。
| 方式名 | 概要 |
|---|---|
キャッシュ
|
対象データの使用頻度が高く不変、または更新頻度が少ない時に有効な方式。キャッシュの実装編は、キャッシュの抽象化(Cache Abstraction) を参照されたい。 (コードリスト等) |
シャーディング
|
対象データがシャードキーで一意に特定される時に有効な方式。シャーディングの実装編は、データベースシャーディング を参照されたい。 (キー項目・特定日付等の完全一致検索を頻繁に行うシステム) |
リードレプリカ
|
対象データをキー項目で特定するのが困難で大量のデータ参照が発生する時に有効な方式。リードレプリカ(参考)の実装編は、データベースリードレプリカ を参照されたい。 (分析・集計等の期間検索を頻繁に行うシステム) |
Note
シャードキーとは、データ固有の識別情報。例えば、ユーザ情報のユーザID等。
3.6.1.1. キャッシュ方式¶
キャッシュ方式とは、使用頻度の高いデータを高速な記憶装置に保持することにより、都度低速な装置から読み出す無駄を省いて高速化する仕組みである。
対象データの使用頻度が高く不変、または更新頻度が少なくデータ変更がシステムに影響しない時に有効な方式である。
3.6.1.1.1. 想定する要件¶
- 不変または更新頻度が少ないデータ(例:マスタデータ、コードリスト)
- 読み込み頻度が高いデータ(例:ログインしているユーザ自身のデータ)
- キーでアクセスすることが可能であるデータ
3.6.1.1.2. 制約¶
- 対象データの更新、削除のタイミングを明示的に宣言する必要がある。
- 対象データの更新、削除時に永続化が別途必要になり、その際にACIDが保たれなくなる可能性がある。
- キー以外での検索に対応できない。
3.6.1.1.3. キャッシュ方式のイメージ¶
以下のイメージは、 Client Application A → Client Application B → Client Application C の順番で同一データを参照する場合を示す。
キャッシュ方式では、Application で指定したキャッシュ設定に従い Cache AOP が Client Application A が要求したデータ参照の結果が Storage Device から取得出来ない場合に Application 経由で DB から結果を取得し Storage Device に保持する。 以降の Client Application B と Client Application C が要求したデータ参照が Client Application A が要求したデータ参照と同じ場合は Cache AOP が Storage Device から結果を取得する。
従来
参照毎に DB にアクセスするため、 DB 負荷が上がる。

キャッシュ方式(SpringのCache抽象を使用)
初回参照時のみ DB にアクセスし、2回目以降は高速な Storage Device から結果を取得する為 DB 負荷も下がる。

3.6.1.2. シャーディング方式¶
シャーディング方式とは、あるデータをキー情報などを元に複数のグループに分割し、グループ毎に異なるDBに分割して保管する方式である。 データアクセスが複数のDBに分散することから、読み取りや書き込みのパフォーマンスが向上したり、単一DBでは実現できない大容量のデータの保管が実現できる
対象データがシャードキーで一意に特定される時に有効な方式である。
3.6.1.2.1. 想定する要件¶
- 各データに対する処理要求に大きな偏りがない、もしくは偏りの傾向が事前予知出来る。
- データセットが大きく単一DBではCPUやI/Oのパフォーマンスが著しく低下する。
- レコード数の増大が見込まれ、単一DBでは容量面でキャパシティオーバーする可能性がある。
3.6.1.2.2. 制約¶
- 各データへの処理要求に偏りがあった場合に、データベースの負荷が均等に分散されない。
- 一連の処理内で複数のシャードに更新を行う場合、ACIDが担保できなくなるため、処理途中のデータの存在を意識したデータモデルや業務処理の設計が必要となる(例:例外発生時のデータの戻し処理を追加)。
- シャードを跨いだテーブルに対して表結合が使えなくなるため、データモデル設計が複雑になったり、それによりJava側でデータの処理が増える可能性がある。
- データアクセスのたびにシャードを選択する処理が必要となるため、処理のオーバヘッドが発生する。
- 各データがどのシャードに所属するかを管理する必要があるため、運用時の手間が発生する。
- シャーディングが不可能なデータを、各シャードとは別のデータベースで別途管理する必要がある(「非シャード」と呼ぶ)。
3.6.1.2.3. シャードキーおよびシャードの決定方針¶
- シャードキーにはシステム全体で一意となる値を採用する。(例:主キー)
- 各シャードの処理性能が均等になるような負荷分散を行えるような振り分けを行う(例えば、全データが均等に処理要求される場合はラウンドロビンで振り分けを行う、など)
3.6.1.2.4. シャードキーの管理方針¶
- シャードキーをインプットとし、シャードを導出可能な形式で管理する。
- 運用上の理由により、あるデータを任意のシャード間で移動した場合に対応できるよう、シャードキーとシャードのマッピング情報の保管には不揮発性な記憶装置を使用する。
- シャード導出のための処理は頻繁に実行されることから、性能向上のためフロントには高速な記憶装置を使用する。
以下に、記憶装置に格納されたデータのイメージを示す。
シャードキー (ユーザID) 値 (データ格納先シャード) ShardA ShardB ShardC ・・・
3.6.1.2.5. シャーディング方式のイメージ¶
シャーディング方式の処理の流れを具体的に説明するため、簡単な例を用いて紹介をする。
多数のユーザ情報(USER)をデータベースで管理しており、このユーザ情報をシャーディング対象とすることで一定の効果を見込めることが判明したため、このデータを複数のデータベースへ均等にシャーディングを行うケースを例として紹介する。
従来
USERが増えると DB へのQUERY発行が集中してしまう。容量がサービス最大値で頭打ちとなる。

シャーディング方式
USERが増えてもグループ毎にアクセスするシャード DB を決めるため、1 DB あたりの負荷が減る。

シャーディング方式を使用する場合、シャードに対してデータアクセスを行う処理のトランザクション境界が、 特定の1シャードのみのアクセスに閉じているか、複数のシャードに跨っているかで、処理設計での考慮ポイントが大きく異なる。
それぞれのパターンを以下に例示し、考慮ポイントを示す。
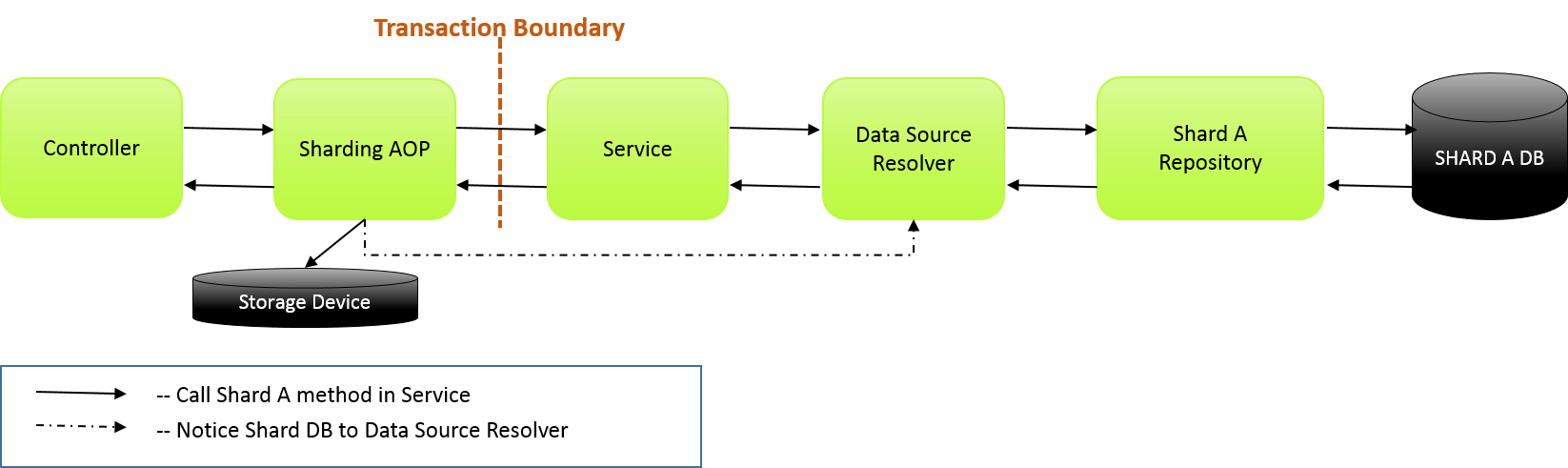
1シャードのみアクセスの処理
1シャードのみアクセスする場合、シャードを選択する処理は行うがシャーディング方式でない場合と同じ様に、Controllerから対象サービスのメソッドを1つだけ呼び出している。
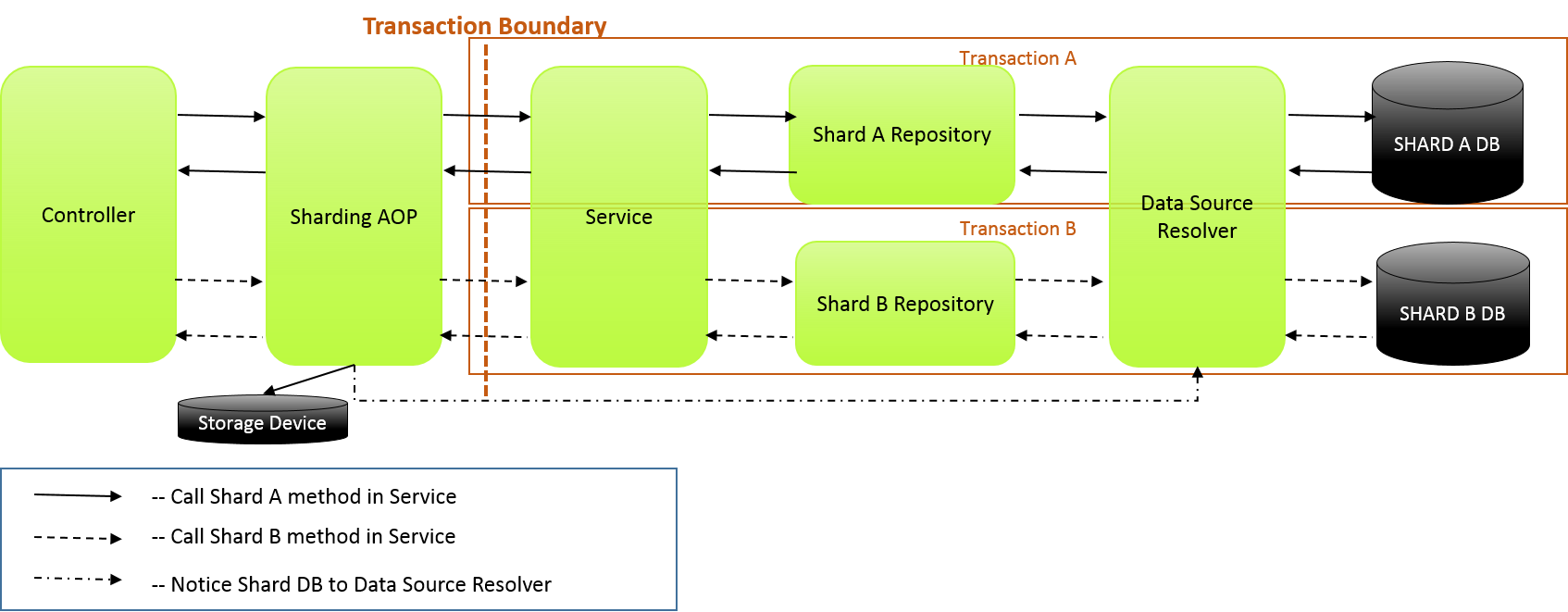
複数シャードに跨ってアクセスする処理
下記、正常系の図に示すように、複数シャードに跨ってアクセスする場合はトランザクション境界でトランザクションが変わることに注意する。
正常系
一連の処理で複数シャードへアクセスする場合は、Controllerから同一または別サービスの別メソッドを呼び出す。 ここでは、同一サービスの別メソッドを呼び出している。
異常系
一連の処理で複数シャードへアクセスした場合に例外が発生した場合は、Controllerで対象データ戻し処理メソッドを呼び出す。 ここでは、Shard B の更新処理で例外が発生した為、既にコミットされているShard A のデータの戻し処理を行う。
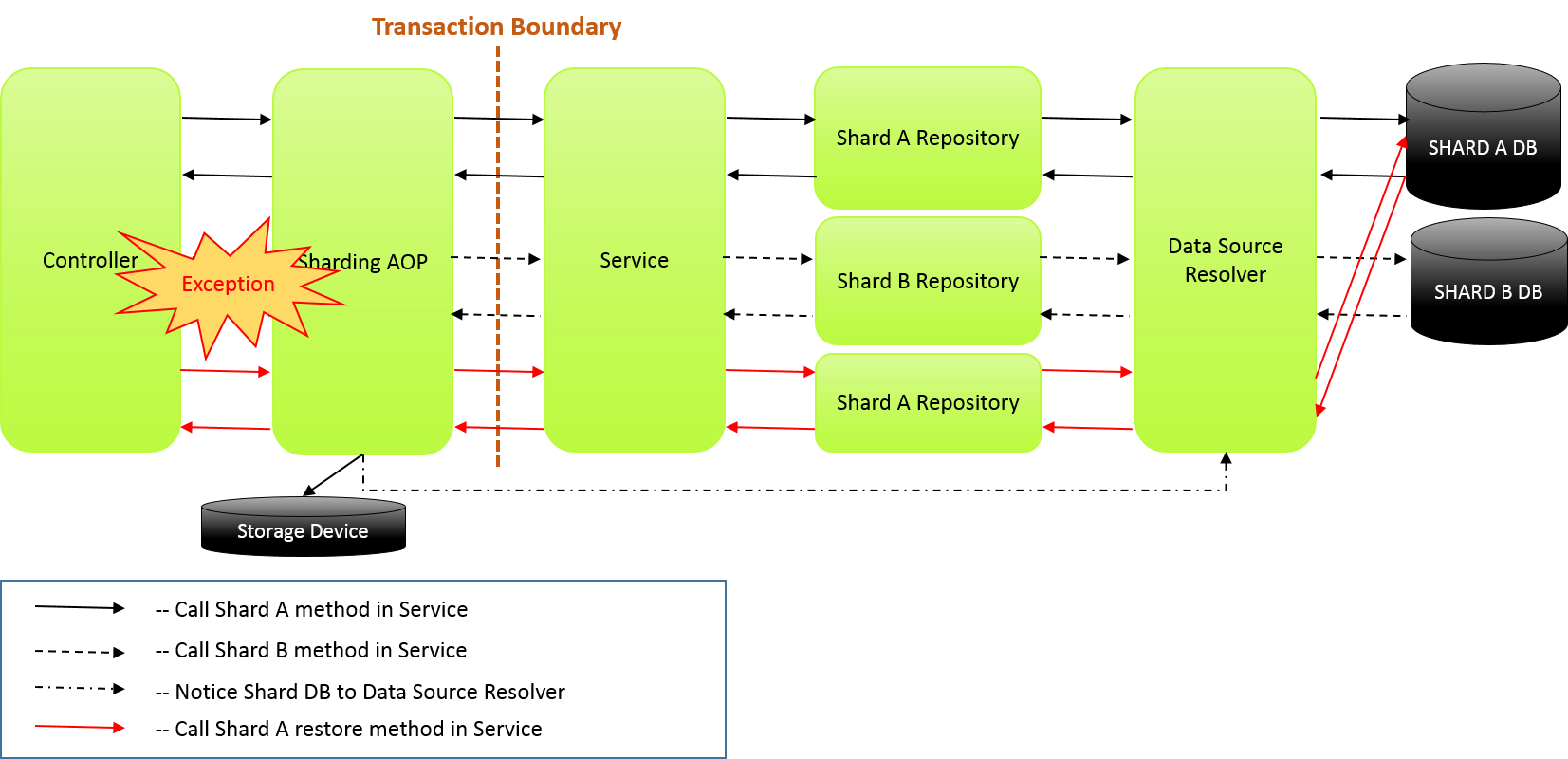
上記では、戻し処理を例に示している。戻し処理以外にも以下のような方法が考えられる。
- 戻し処理を行わず、ジャーナルのような履歴等で処理状態を管理することで障害を無視させる方法
- 全てのデータが登録されていないと、後続の処理が失敗するようなフェイルセーフな設計とする方法
また、戻し処理を行う場合でも、戻し処理に失敗した場合や戻し処理前に実行した非同期処理等に考慮が必要となる。
考慮ポイント
- Shard AとShard Bのトランザクション境界が別となるため、Shard Aのコミット後にShard Bがロールバックする可能性がある。Shard AとShard Bのデータの一貫性が担保されない状態となるため、システム要件やデータの特性に合わせ、必要に応じて整合性が正しい状態に戻す。
- 障害有無にかかわらず、別トランザクションな時点でACIDな整合性は崩れている(同時に別スレッドでデータを読み書きした場合、処理中の状態が見えてしまう)ので、異常時だけ考慮すればよいというものではなく、そもそもACIDでなくても業務に影響がないことを考慮する必要がある。
- シャード対象の選定、データモデルの設計、データ処理の順序などを考慮する。
3.6.1.3. リードレプリカ方式¶
リードレプリカ方式とは、複数DBに同一データを保持し読み取りDBと書き込みDBを別にする事によりパフォーマンスを向上させる仕組みである。読み取り専用のDBをレプリカDB、書込み可能なDBをマスタDBと呼ぶ。
対象データをキー項目で特定するのが困難で大量のデータ参照が発生する時に有効な方式である。
3.6.1.3.1. 想定する要件¶
- データ分析等の、レコード更新よりもレコード参照のリクエスト数が圧倒的に多い。
- 容量面において、単一DBのキャパシティオーバーする可能性がない。
- データ参照時に常に最新のデータが取得できなくても業務に支障をきたさない。
3.6.1.3.2. 制約¶
- 一連の処理(1つのトランザクション)内で参照と更新を行う場合、レプリカDBの参照は出来ない。
- データベースの負荷が均等に分散されないことや、書き込んだデータがリードレプリカDBに反映されるまでに時間差がある。
- レプリカDBの台数は製品により上限がある
3.6.1.3.3. リードレプリカDBの決定方針¶
- リードレプリカDBのスペックは、マスタDBのスペックと同等にする。
- リードレプリカDBの本数は、queryの処理時間、処理数と並列処理等を考慮して決定する。
3.6.1.3.4. リードレプリカ方式のイメージ¶
従来
集計・分析等の大量レコード参照のアクセス数が増えると DB でのQUERY処理が終了せず、更新処理にも影響が及ぶ。

リードレプリカ方式
集計・分析等の大量レコード参照のアクセス数が増えても READ REPLICA DB でQUERY処理が行われるため、更新処理には影響が及ばない。

3.6.2. How to use¶
3.6.2.1. クラウドベンダーの利用¶
クラウドベンダー提供のデータベースサービスを利用する場合のガイドラインについて、記載箇所を示しておく。
3.6.2.1.1. Amazon Web Service¶
クラウドベンダーとしてAWSを使用する場合のデータベースシャーディングについては、 データベースシャーディング を、リードレプリカについては、 データベースリードレプリカ を参照されたい。